
环境说明#
- Kubernetes 版本:v1.19.6
- 操作系统:CentOS 7.9.2009
问题现象#
最近在使用 Kubernetes 集群时,发现集群响应变慢。排查发现 Master 节点中 controller-manager 及 scheduler 组件频繁重启。
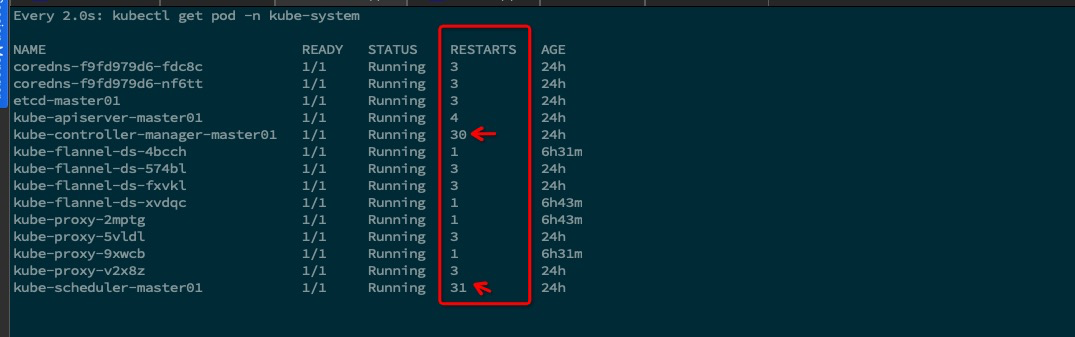
排查过程#
收集日志信息#
使用重定向将日志写入文件中进行分析(一开始使用前台抓取,日志太长超出了终端的默认显示行数):
kubectl logs -f kube-controller-manager-master01 -n kube-system >> controller.log
错误信息分析#
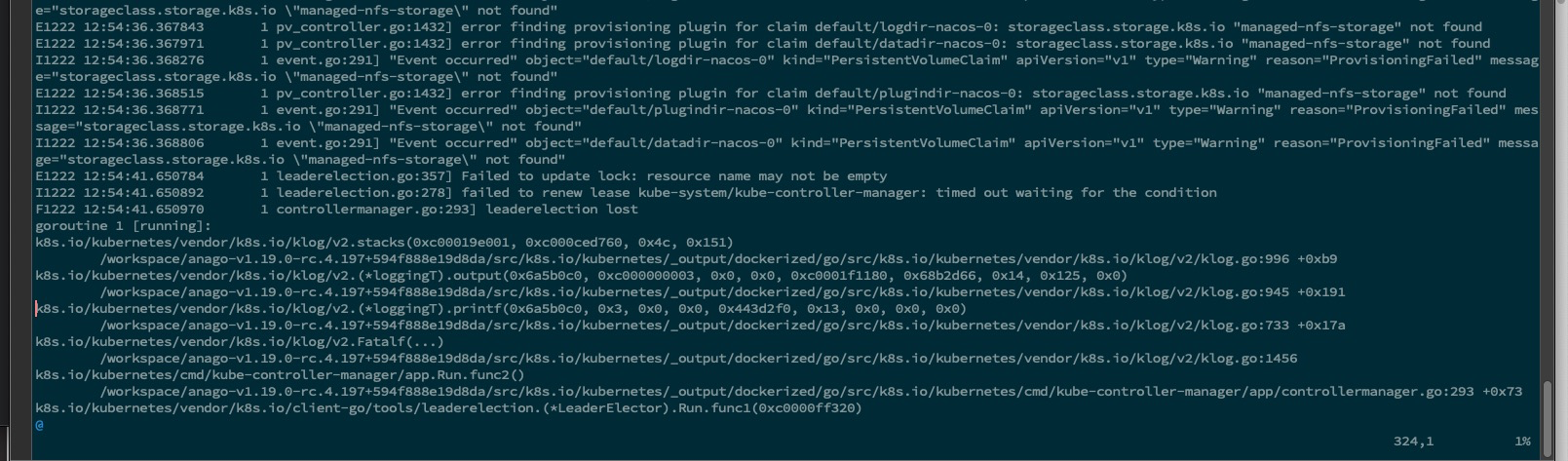
通过搜索引擎查找,有人说是 etcd 性能导致的问题。尝试使用此文档进行 etcd 优化,但没有效果。
检测网络和 IO#
安装监控工具#
yum install dstat iotop -y
# 检查 IO 使用情况
iotop -oP
# 显示所有网络接口使用情况
dstat -nf
# 显示所有磁盘使用情况,当接口过多时可使用 "-N" 指定网口,"-D" 指定磁盘
dstat -df
发现问题根源#
排查发现 IO 占用很高,且被 flanneld 进程占用:

确认问题来源#
发现社区也有人反馈这个问题,但目前暂时没有人员回复:
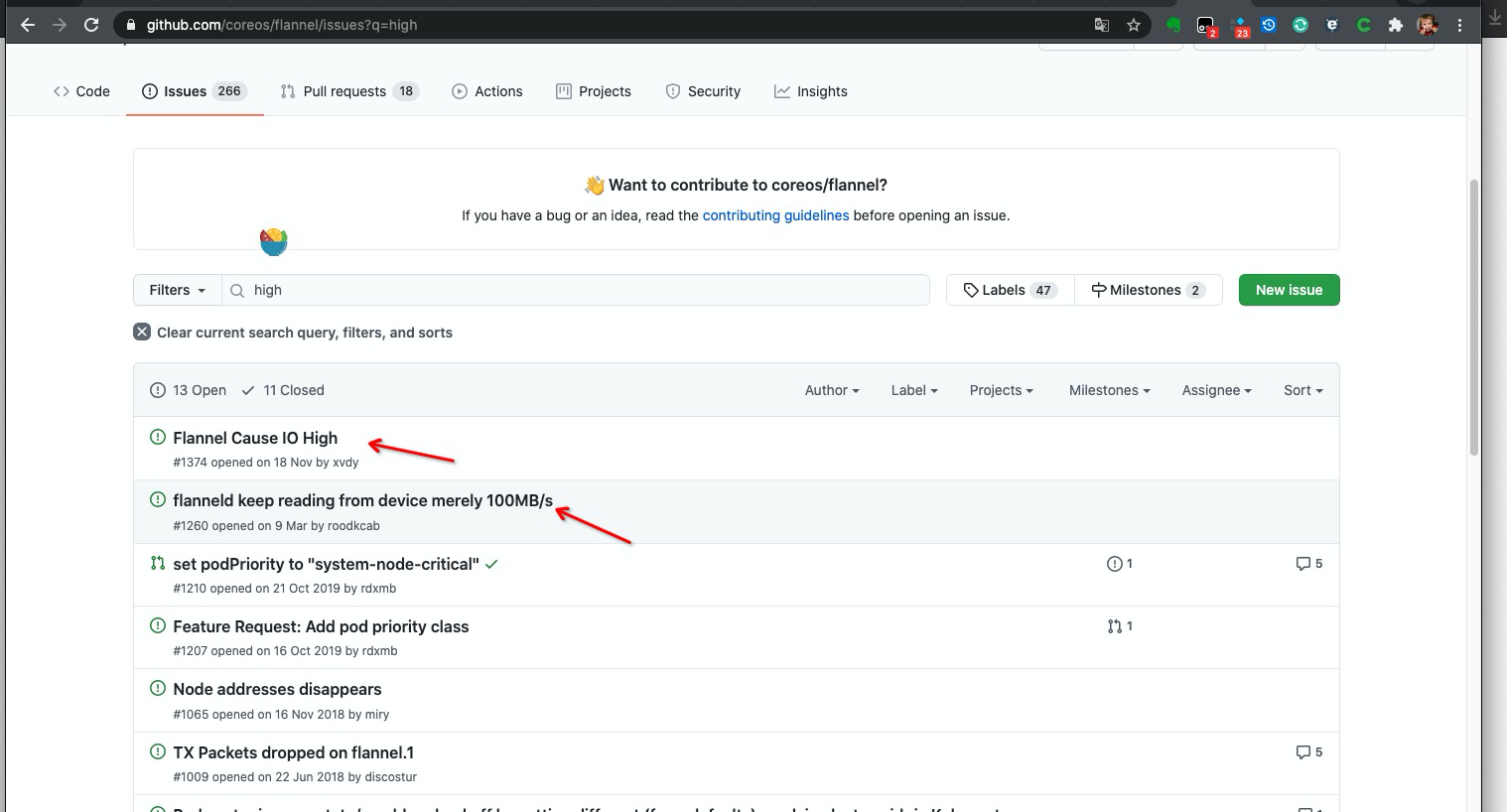
临时验证解决方案#
为了验证问题确实来自 Flannel,先临时删除 Flannel:
kubectl delete -f https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml
ifconfig cni0 down
ip link delete cni0
ifconfig flannel.1 down
ip link delete flannel.1
rm -rf /var/lib/cni/
rm -f /etc/cni/net.d/*
systemctl restart kubelet
删除 Flannel 后,各节点的 IO 恢复正常,确认问题就是 Flannel 导致的。但是 Flannel 组件不可缺少,需要找到解决方案重新安装。
解决方案#
检查当前使用的版本#

方案一:降级版本#
尝试使用较低版本的 Flannel:
# 如果修改了默认的 Pod 子网地址,需要替换子网配置
curl https://raw.githubusercontent.com/coreos/flannel/v0.13.0/Documentation/kube-flannel.yml | sed 's#10.244.0.0/16#172.20.0.0/16#g' | kubectl apply -f -
# 如果使用默认子网,直接应用即可
kubectl apply -f https://raw.githubusercontent.com/coreos/flannel/v0.13.0/Documentation/kube-flannel.yml
# 等待 Pod 启动完成
watch kubectl get pod -n kube-system
启动完成后,再次使用 iotop -oP 观察 IO 是否异常,确认正常后观察 controller-manager 是否会再次发生重启:
kubectl logs -f kube-controller-manager-master01 -n kube-system > controller.log
方案二:绑定网卡(推荐)#
降低 Flannel 版本后,仍然会出现 IO 较高的情况。经过测试发现,这是因为集群机器中存在多张网卡导致的。
解决方法:在 Flannel 资源清单中添加 --iface=ethX 来绑定指定网卡,这要求集群中每个节点都存在此网卡。
下载并修改配置文件#
wget https://raw.githubusercontent.com/coreos/flannel/v0.13.0/Documentation/kube-flannel.yml
vim kube-flannel.yml
修改配置#
在容器启动参数中添加网卡绑定:
containers:
- name: kube-flannel
image: quay.io/coreos/flannel:v0.13.0
command:
- /opt/bin/flanneld
args:
- --ip-masq
- --kube-subnet-mgr
- --iface=eth0 # 添加此行,绑定到 eth0 网卡
重新部署#
kubectl apply -f kube-flannel.yml
解决结果#
执行网卡绑定配置后,IO 占用高的情况得到解决,控制平面组件不再频繁重启。
总结#
本次问题的根本原因是 Flannel 在多网卡环境下选择网卡时出现异常,导致 IO 占用过高,进而影响 etcd 性能,最终导致控制平面组件频繁重启。
解决方案:
- 临时方案:降级 Flannel 版本
- 根本方案:通过
--iface参数明确指定 Flannel 使用的网卡
经验总结:
- 在多网卡环境下部署 Kubernetes 时,建议明确指定网络组件使用的网卡
- 遇到控制平面组件异常时,应该从底层资源(CPU、内存、IO、网络)开始排查
- 网络组件的配置问题可能会影响整个集群的稳定性