
Apache Kafka 简介#
什么是 Apache Kafka#
Apache Kafka 是一个开源的分布式事件流处理平台,由 LinkedIn 开发并贡献给 Apache 软件基金会。它被数千家公司用于高性能数据管道、流分析、数据集成和关键任务应用程序。
核心特性#
- 高吞吐量:单个节点可处理每秒数百万条消息
- 低延迟:端到端延迟通常在几毫秒内
- 持久性:消息持久化存储在磁盘,支持数据回放和恢复
- 分布式架构:天然支持集群部署,具备水平扩展能力
- 容错性:通过副本机制保证数据不丢失
- 实时处理:支持实时流处理和批处理
应用场景#
- 消息队列:解耦系统组件,提高系统可靠性
- 日志聚合:收集和处理来自多个服务的日志数据
- 流处理:实时处理和分析数据流
- 事件溯源:记录系统状态变化的完整历史
- 数据管道:在不同系统间可靠地传输数据
- 微服务通信:作为微服务架构中的消息总线
架构概述#
Kafka 核心组件#
flowchart TB
subgraph Producers[Producers]
P1[Producer 1]
P2[Producer 2]
P3[Producer 3]
end
subgraph KafkaCluster[Kafka Cluster]
B1[Broker 1
Topic A/B]
B2[Broker 2
Topic A/B]
B3[Broker 3
Topic A/B]
end
subgraph Consumers[Consumers]
C1[Consumer 1]
C2[Consumer 2]
C3[Consumer 3]
end
subgraph ZooKeeper[ZooKeeper Cluster]
Z1[ZK 1]
Z2[ZK 2]
Z3[ZK 3]
end
P1 --> KafkaCluster
P2 --> KafkaCluster
P3 --> KafkaCluster
KafkaCluster --> C1
KafkaCluster --> C2
KafkaCluster --> C3
KafkaCluster -.-> ZooKeeper
部署方案选择#
本指南采用以下企业级技术栈:
| 组件 | 选择方案 | 说明 |
|---|---|---|
| 部署工具 | Confluent Helm Charts | Confluent 官方维护的 K8s 部署方案 |
| 包管理 | Helm 3.x | Kubernetes 应用包管理工具 |
| 管理界面 | Kafka Manager (CMAK) | 可视化集群管理和监控工具 |
| 监控方案 | Prometheus + Grafana | 完整的监控和告警体系 |
| 存储方案 | 持久化卷 (PV/PVC) | 保证数据持久性和高可用 |
环境准备#
系统要求#
基础环境#
| 组件 | 最低版本 | 推荐版本 | 说明 |
|---|---|---|---|
| Kubernetes | v1.17.4 | v1.21.0+ | 容器编排平台 |
| Helm | v3.3.1 | v3.7.0+ | Kubernetes 包管理工具 |
| kubectl | v1.17.4 | v1.21.0+ | Kubernetes 命令行工具 |
| Docker | 18.09.6 | 20.10.0+ | 容器运行时 |
存储要求#
| 存储类型 | 用途 | 性能要求 | 推荐方案 |
|---|---|---|---|
| Kafka 数据存储 | 消息持久化 | 高 IOPS,低延迟 | SSD,NVMe |
| ZooKeeper 存储 | 元数据存储 | 中等 IOPS | SSD |
| 日志存储 | 应用日志 | 低 IOPS | HDD |
网络要求#
- 集群内通信:Kafka 节点间需要高带宽、低延迟网络
- 外部访问:支持 LoadBalancer 或 Ingress 控制器
- 端口规划:
- Kafka: 9092 (内部), 9094 (外部)
- ZooKeeper: 2181, 2888, 3888
- Kafka Manager: 9000
资源规划#
生产环境推荐配置#
Kafka 节点:
- CPU: 4-8 核心
- 内存: 8-16GB RAM
- 存储: 500GB-2TB SSD
- 网络: 1Gbps+
ZooKeeper 节点:
- CPU: 2-4 核心
- 内存: 4-8GB RAM
- 存储: 100-500GB SSD
- 网络: 1Gbps
管理节点:
- CPU: 2 核心
- 内存: 2-4GB RAM
- 存储: 50GB
- 网络: 100Mbps
集群规模建议#
| 环境类型 | Kafka 节点 | ZooKeeper 节点 | 副本因子 | 分区数建议 |
|---|---|---|---|---|
| 开发环境 | 1 | 1 | 1 | 1-10 |
| 测试环境 | 3 | 3 | 2 | 10-50 |
| 生产环境 | 3-9 | 3-5 | 3 | 50-1000+ |
前置条件检查#
创建检查脚本#
cat > check-prerequisites.sh << 'EOF'
#!/bin/bash
echo "=== Kubernetes 集群环境检查 ==="
# 检查 kubectl 连接
echo "检查 kubectl 连接..."
if kubectl cluster-info >/dev/null 2>&1; then
echo "✓ kubectl 连接正常"
kubectl version --short
else
echo "✗ kubectl 连接失败"
exit 1
fi
# 检查 Helm
echo -e "\n检查 Helm 版本..."
if command -v helm >/dev/null 2>&1; then
echo "✓ Helm 已安装"
helm version --short
else
echo "✗ Helm 未安装"
exit 1
fi
# 检查节点资源
echo -e "\n检查节点资源..."
kubectl top nodes 2>/dev/null || echo "注意: metrics-server 未安装,无法显示资源使用情况"
# 检查存储类
echo -e "\n检查存储类..."
kubectl get storageclass
if [ $? -eq 0 ]; then
echo "✓ 存储类配置正常"
else
echo "✗ 存储类配置异常"
fi
# 检查命名空间
echo -e "\n检查目标命名空间..."
NAMESPACE="kafka-cluster"
if kubectl get namespace $NAMESPACE >/dev/null 2>&1; then
echo "✓ 命名空间 $NAMESPACE 已存在"
else
echo "! 命名空间 $NAMESPACE 不存在,将自动创建"
fi
echo -e "\n=== 环境检查完成 ==="
EOF
chmod +x check-prerequisites.sh
./check-prerequisites.sh
部署实施#
步骤 1:准备 Helm Charts#
获取官方 Charts#
# 创建工作目录
mkdir -p ~/kafka-k8s-deploy && cd ~/kafka-k8s-deploy
# 添加 Confluent Helm 仓库
helm repo add confluentinc https://confluentinc.github.io/cp-helm-charts/
helm repo update
# 下载 Charts 到本地(可选,用于自定义)
helm pull confluentinc/cp-helm-charts --untar
# 查看可用版本
helm search repo confluentinc/cp-helm-charts --versions
查看默认配置#
# 查看默认配置
helm show values confluentinc/cp-helm-charts > default-values.yaml
# 查看 Chart 信息
helm show chart confluentinc/cp-helm-charts
步骤 2:镜像准备(离线环境)#
自动化镜像处理脚本#
cat > manage-images.sh << 'EOF'
#!/bin/bash
# 配置变量
PRIVATE_REGISTRY="your-registry.com"
NAMESPACE="kafka-cluster"
CHART_NAME="confluentinc/cp-helm-charts"
# 镜像列表(根据实际版本调整)
IMAGES=(
"confluentinc/cp-zookeeper:7.2.1"
"confluentinc/cp-kafka:7.2.1"
"confluentinc/cp-kafka-connect:7.2.1"
"confluentinc/cp-schema-registry:7.2.1"
"confluentinc/cp-kafka-rest:7.2.1"
"confluentinc/cp-ksqldb-server:7.2.1"
"confluentinc/cp-control-center:7.2.1"
"provectuslabs/kafka-ui:latest"
"solsson/kafka-prometheus-jmx-exporter:0.17.0"
)
# 函数:拉取镜像
pull_images() {
echo "=== 拉取镜像 ==="
for image in "${IMAGES[@]}"; do
echo "拉取镜像: $image"
docker pull "$image"
done
}
# 函数:标记并推送到私有仓库
push_to_private() {
echo "=== 推送到私有仓库 ==="
for image in "${IMAGES[@]}"; do
# 提取镜像名和标签
image_name=$(echo "$image" | cut -d'/' -f2-)
private_image="$PRIVATE_REGISTRY/$image_name"
echo "标记镜像: $image -> $private_image"
docker tag "$image" "$private_image"
echo "推送镜像: $private_image"
docker push "$private_image"
done
}
# 函数:导出镜像包
export_images() {
echo "=== 导出镜像包 ==="
docker save "${IMAGES[@]}" | gzip > kafka-images-$(date +%Y%m%d).tar.gz
echo "镜像包已保存为: kafka-images-$(date +%Y%m%d).tar.gz"
}
# 函数:导入镜像包
import_images() {
if [ -f "$1" ]; then
echo "=== 导入镜像包 ==="
docker load < "$1"
echo "镜像包导入完成"
else
echo "错误: 镜像包文件不存在: $1"
exit 1
fi
}
# 函数:生成镜像配置
generate_image_config() {
cat > image-overrides.yaml << 'YAML'
# 镜像配置覆盖文件
cp-zookeeper:
image: your-registry.com/confluentinc/cp-zookeeper
imageTag: "7.2.1"
cp-kafka:
image: your-registry.com/confluentinc/cp-kafka
imageTag: "7.2.1"
cp-kafka-connect:
image: your-registry.com/confluentinc/cp-kafka-connect
imageTag: "7.2.1"
cp-schema-registry:
image: your-registry.com/confluentinc/cp-schema-registry
imageTag: "7.2.1"
cp-kafka-rest:
image: your-registry.com/confluentinc/cp-kafka-rest
imageTag: "7.2.1"
cp-ksql-server:
image: your-registry.com/confluentinc/cp-ksqldb-server
imageTag: "7.2.1"
cp-control-center:
image: your-registry.com/confluentinc/cp-control-center
imageTag: "7.2.1"
YAML
echo "镜像配置文件已生成: image-overrides.yaml"
}
# 主菜单
case "$1" in
pull)
pull_images
;;
push)
push_to_private
;;
export)
export_images
;;
import)
import_images "$2"
;;
config)
generate_image_config
;;
all)
pull_images
export_images
generate_image_config
;;
*)
echo "用法: $0 {pull|push|export|import <file>|config|all}"
echo " pull - 拉取所有镜像"
echo " push - 推送到私有仓库"
echo " export - 导出镜像包"
echo " import - 导入镜像包"
echo " config - 生成镜像配置文件"
echo " all - 执行 pull + export + config"
exit 1
;;
esac
EOF
chmod +x manage-images.sh
# 使用示例
# ./manage-images.sh pull # 拉取镜像
# ./manage-images.sh export # 导出镜像包
# ./manage-images.sh config # 生成配置文件
最小化部署镜像列表#
对于最小化部署,只需要以下核心镜像:
# 核心组件镜像
cat > minimal-images.txt << 'EOF'
confluentinc/cp-zookeeper:7.2.1
confluentinc/cp-kafka:7.2.1
provectuslabs/kafka-ui:latest
solsson/kafka-prometheus-jmx-exporter:0.17.0
EOF
# 批量处理最小化镜像
cat > process-minimal-images.sh << 'EOF'
#!/bin/bash
REGISTRY="your-registry.com"
echo "处理最小化镜像列表..."
while IFS= read -r image; do
echo "处理镜像: $image"
docker pull "$image"
# 标记为私有仓库镜像
private_image="$REGISTRY/$image"
docker tag "$image" "$private_image"
docker push "$private_image"
done < minimal-images.txt
echo "最小化镜像处理完成"
EOF
chmod +x process-minimal-images.sh
步骤 3:配置部署参数#
创建命名空间#
# 创建专用命名空间
kubectl create namespace kafka-cluster
# 设置默认命名空间(可选)
kubectl config set-context --current --namespace=kafka-cluster
开发环境配置#
cat > kafka-dev-values.yaml << 'EOF'
# Kafka 开发环境配置
cp-kafka:
enabled: true
servers: 1
image: confluentinc/cp-kafka
imageTag: 7.2.1
heapOptions: "-Xms512M -Xmx1G"
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 1000m
memory: 2Gi
persistence:
enabled: true
size: 10Gi
storageClass: "standard"
configurationOverrides:
"offsets.topic.replication.factor": "1"
"transaction.state.log.replication.factor": "1"
"transaction.state.log.min.isr": "1"
"default.replication.factor": "1"
"min.insync.replicas": "1"
# ZooKeeper 配置
cp-zookeeper:
enabled: true
servers: 1
image: confluentinc/cp-zookeeper
imageTag: 7.2.1
heapOptions: "-Xms256M -Xmx512M"
resources:
requests:
cpu: 250m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
persistence:
enabled: true
dataDirSize: 5Gi
dataLogDirSize: 5Gi
dataDirStorageClass: "standard"
dataLogDirStorageClass: "standard"
# 禁用不需要的组件
cp-kafka-rest:
enabled: false
cp-kafka-connect:
enabled: false
cp-schema-registry:
enabled: false
cp-ksql-server:
enabled: false
cp-control-center:
enabled: false
EOF
生产环境配置#
cat > kafka-prod-values.yaml << 'EOF'
# Kafka 生产环境配置
cp-kafka:
enabled: true
servers: 3
image: confluentinc/cp-kafka
imageTag: 7.2.1
heapOptions: "-Xms4G -Xmx4G"
resources:
requests:
cpu: 2000m
memory: 6Gi
limits:
cpu: 4000m
memory: 8Gi
persistence:
enabled: true
size: 500Gi
storageClass: "fast-ssd"
configurationOverrides:
"auto.create.topics.enable": "false"
"offsets.topic.replication.factor": "3"
"transaction.state.log.replication.factor": "3"
"transaction.state.log.min.isr": "2"
"default.replication.factor": "3"
"min.insync.replicas": "2"
"unclean.leader.election.enable": "false"
"log.retention.hours": "168"
"log.segment.bytes": "1073741824"
"log.retention.check.interval.ms": "300000"
"num.network.threads": "8"
"num.io.threads": "16"
"socket.send.buffer.bytes": "102400"
"socket.receive.buffer.bytes": "102400"
"socket.request.max.bytes": "104857600"
"num.partitions": "3"
"num.recovery.threads.per.data.dir": "1"
"log.flush.interval.messages": "10000"
"log.flush.interval.ms": "1000"
# ZooKeeper 生产配置
cp-zookeeper:
enabled: true
servers: 3
image: confluentinc/cp-zookeeper
imageTag: 7.2.1
heapOptions: "-Xms1G -Xmx1G"
resources:
requests:
cpu: 1000m
memory: 2Gi
limits:
cpu: 2000m
memory: 4Gi
persistence:
enabled: true
dataDirSize: 100Gi
dataLogDirSize: 100Gi
dataDirStorageClass: "fast-ssd"
dataLogDirStorageClass: "fast-ssd"
# Schema Registry(可选)
cp-schema-registry:
enabled: true
image: confluentinc/cp-schema-registry
imageTag: 7.2.1
heapOptions: "-Xms512M -Xmx1G"
resources:
requests:
cpu: 500m
memory: 1Gi
limits:
cpu: 1000m
memory: 2Gi
# Kafka Connect(可选)
cp-kafka-connect:
enabled: true
image: confluentinc/cp-kafka-connect
imageTag: 7.2.1
heapOptions: "-Xms1G -Xmx2G"
resources:
requests:
cpu: 1000m
memory: 2Gi
limits:
cpu: 2000m
memory: 4Gi
# 禁用不需要的组件
cp-kafka-rest:
enabled: false
cp-ksql-server:
enabled: false
cp-control-center:
enabled: false
EOF
高可用配置(企业级)#
cat > kafka-ha-values.yaml << 'EOF'
# Kafka 高可用企业级配置
cp-kafka:
enabled: true
servers: 5
image: confluentinc/cp-kafka
imageTag: 7.2.1
heapOptions: "-Xms6G -Xmx6G"
resources:
requests:
cpu: 4000m
memory: 8Gi
limits:
cpu: 8000m
memory: 12Gi
persistence:
enabled: true
size: 1Ti
storageClass: "premium-ssd"
# 反亲和性配置
podAntiAffinity: "hard"
# 节点选择器
nodeSelector:
kafka-node: "true"
# 容忍度配置
tolerations:
- key: "kafka-dedicated"
operator: "Equal"
value: "true"
effect: "NoSchedule"
configurationOverrides:
"auto.create.topics.enable": "false"
"offsets.topic.replication.factor": "3"
"transaction.state.log.replication.factor": "3"
"transaction.state.log.min.isr": "2"
"default.replication.factor": "3"
"min.insync.replicas": "2"
"unclean.leader.election.enable": "false"
"log.retention.hours": "168"
"log.segment.bytes": "1073741824"
"num.network.threads": "16"
"num.io.threads": "32"
"socket.send.buffer.bytes": "102400"
"socket.receive.buffer.bytes": "102400"
"socket.request.max.bytes": "104857600"
"num.partitions": "5"
"compression.type": "lz4"
"log.cleanup.policy": "delete"
"log.retention.check.interval.ms": "300000"
# ZooKeeper 高可用配置
cp-zookeeper:
enabled: true
servers: 5
image: confluentinc/cp-zookeeper
imageTag: 7.2.1
heapOptions: "-Xms2G -Xmx2G"
resources:
requests:
cpu: 2000m
memory: 4Gi
limits:
cpu: 4000m
memory: 6Gi
persistence:
enabled: true
dataDirSize: 200Gi
dataLogDirSize: 200Gi
dataDirStorageClass: "premium-ssd"
dataLogDirStorageClass: "premium-ssd"
# 反亲和性配置
podAntiAffinity: "hard"
# 节点选择器
nodeSelector:
zookeeper-node: "true"
# 启用完整的 Confluent Platform
cp-schema-registry:
enabled: true
replicaCount: 3
image: confluentinc/cp-schema-registry
imageTag: 7.2.1
cp-kafka-connect:
enabled: true
replicaCount: 3
image: confluentinc/cp-kafka-connect
imageTag: 7.2.1
cp-kafka-rest:
enabled: true
replicaCount: 2
image: confluentinc/cp-kafka-rest
imageTag: 7.2.1
cp-ksql-server:
enabled: true
replicaCount: 2
image: confluentinc/cp-ksqldb-server
imageTag: 7.2.1
cp-control-center:
enabled: true
image: confluentinc/cp-control-center
imageTag: 7.2.1
EOF
步骤 4:执行部署#
部署命令#
# 开发环境部署
helm upgrade --install kafka-dev \
confluentinc/cp-helm-charts \
-f kafka-dev-values.yaml \
-n kafka-cluster \
--create-namespace
# 生产环境部署
helm upgrade --install kafka-prod \
confluentinc/cp-helm-charts \
-f kafka-prod-values.yaml \
-n kafka-cluster \
--create-namespace
# 高可用环境部署
helm upgrade --install kafka-ha \
confluentinc/cp-helm-charts \
-f kafka-ha-values.yaml \
-n kafka-cluster \
--create-namespace
部署验证#
# 查看部署状态
helm list -n kafka-cluster
# 查看 Pod 状态
kubectl get pods -n kafka-cluster -w
# 查看服务状态
kubectl get svc -n kafka-cluster
# 查看持久化卷
kubectl get pvc -n kafka-cluster
# 查看详细信息
kubectl describe deployment -n kafka-cluster

管理工具部署#
Kafka UI 部署(推荐)#
现代化管理界面#
Kafka UI 是一个现代化的 Kafka 集群管理工具,提供直观的 Web 界面。
cat > kafka-ui-deployment.yaml << 'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-ui
namespace: kafka-cluster
labels:
app: kafka-ui
spec:
replicas: 1
selector:
matchLabels:
app: kafka-ui
template:
metadata:
labels:
app: kafka-ui
spec:
containers:
- name: kafka-ui
image: provectuslabs/kafka-ui:latest
ports:
- containerPort: 8080
env:
- name: KAFKA_CLUSTERS_0_NAME
value: "kafka-cluster"
- name: KAFKA_CLUSTERS_0_BOOTSTRAPSERVERS
value: "kafka-dev-cp-kafka:9092"
- name: KAFKA_CLUSTERS_0_ZOOKEEPER
value: "kafka-dev-cp-zookeeper:2181"
- name: KAFKA_CLUSTERS_0_READONLY
value: "false"
- name: KAFKA_CLUSTERS_0_KAFKACONNECT_0_NAME
value: "kafka-connect"
- name: KAFKA_CLUSTERS_0_KAFKACONNECT_0_ADDRESS
value: "http://kafka-dev-cp-kafka-connect:8083"
- name: KAFKA_CLUSTERS_0_SCHEMAREGISTRY
value: "http://kafka-dev-cp-schema-registry:8081"
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
livenessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 60
periodSeconds: 30
readinessProbe:
httpGet:
path: /actuator/health
port: 8080
initialDelaySeconds: 30
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: kafka-ui
namespace: kafka-cluster
labels:
app: kafka-ui
spec:
type: ClusterIP
ports:
- port: 8080
targetPort: 8080
protocol: TCP
name: http
selector:
app: kafka-ui
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kafka-ui
namespace: kafka-cluster
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/rewrite-target: /
nginx.ingress.kubernetes.io/ssl-redirect: "false"
spec:
rules:
- host: kafka-ui.your-domain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kafka-ui
port:
number: 8080
EOF
部署 Kafka UI#
# 部署 Kafka UI
kubectl apply -f kafka-ui-deployment.yaml
# 查看部署状态
kubectl get pods -n kafka-cluster -l app=kafka-ui
# 查看服务
kubectl get svc -n kafka-cluster kafka-ui
# 端口转发(本地访问)
kubectl port-forward -n kafka-cluster svc/kafka-ui 8080:8080
Kafka Manager (CMAK) 部署(备选)#
传统管理工具#
cat > kafka-manager-deployment.yaml << 'EOF'
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-manager
namespace: kafka-cluster
labels:
app: kafka-manager
spec:
replicas: 1
selector:
matchLabels:
app: kafka-manager
template:
metadata:
labels:
app: kafka-manager
spec:
containers:
- name: kafka-manager
image: hlebalbau/kafka-manager:stable
ports:
- containerPort: 9000
env:
- name: ZK_HOSTS
value: "kafka-dev-cp-zookeeper:2181"
- name: APPLICATION_SECRET
value: "random-secret-key-change-in-production"
- name: KM_ARGS
value: "-Djava.net.preferIPv4Stack=true"
resources:
requests:
cpu: 200m
memory: 512Mi
limits:
cpu: 500m
memory: 1Gi
livenessProbe:
httpGet:
path: /
port: 9000
initialDelaySeconds: 60
periodSeconds: 30
readinessProbe:
httpGet:
path: /
port: 9000
initialDelaySeconds: 30
periodSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: kafka-manager
namespace: kafka-cluster
labels:
app: kafka-manager
spec:
type: ClusterIP
ports:
- port: 9000
targetPort: 9000
protocol: TCP
name: http
selector:
app: kafka-manager
---
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kafka-manager
namespace: kafka-cluster
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/auth-type: basic
nginx.ingress.kubernetes.io/auth-secret: kafka-manager-auth
nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required'
spec:
rules:
- host: kafka-manager.your-domain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kafka-manager
port:
number: 9000
EOF
创建认证密钥#
# 创建基本认证密钥
htpasswd -c auth admin
kubectl create secret generic kafka-manager-auth \
--from-file=auth \
-n kafka-cluster
# 部署 Kafka Manager
kubectl apply -f kafka-manager-deployment.yaml
监控工具部署#
Prometheus JMX Exporter#
cat > kafka-monitoring.yaml << 'EOF'
apiVersion: v1
kind: ConfigMap
metadata:
name: kafka-jmx-config
namespace: kafka-cluster
data:
kafka-jmx-config.yml: |
rules:
- pattern: kafka.server<type=(.+), name=(.+)PerSec, topic=(.+)><>Count
name: kafka_server_$1_$2_per_sec
type: COUNTER
labels:
topic: "$3"
- pattern: kafka.server<type=(.+), name=(.+)PerSec><>Count
name: kafka_server_$1_$2_per_sec
type: COUNTER
- pattern: kafka.server<type=(.+), name=(.+), topic=(.+), partition=(.+)><>Value
name: kafka_server_$1_$2
type: GAUGE
labels:
topic: "$3"
partition: "$4"
- pattern: kafka.server<type=(.+), name=(.+)><>Value
name: kafka_server_$1_$2
type: GAUGE
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: kafka-jmx-exporter
namespace: kafka-cluster
spec:
replicas: 1
selector:
matchLabels:
app: kafka-jmx-exporter
template:
metadata:
labels:
app: kafka-jmx-exporter
spec:
containers:
- name: kafka-jmx-exporter
image: solsson/kafka-prometheus-jmx-exporter:0.17.0
ports:
- containerPort: 5556
volumeMounts:
- name: config
mountPath: /etc/jmx-kafka
env:
- name: JMX_PORT
value: "5555"
- name: CONFIG_YML
value: "/etc/jmx-kafka/kafka-jmx-config.yml"
resources:
requests:
cpu: 100m
memory: 128Mi
limits:
cpu: 200m
memory: 256Mi
volumes:
- name: config
configMap:
name: kafka-jmx-config
---
apiVersion: v1
kind: Service
metadata:
name: kafka-jmx-exporter
namespace: kafka-cluster
labels:
app: kafka-jmx-exporter
spec:
ports:
- port: 5556
targetPort: 5556
name: metrics
selector:
app: kafka-jmx-exporter
EOF
kubectl apply -f kafka-monitoring.yaml
部署验证#
# 查看所有管理工具状态
kubectl get pods -n kafka-cluster -l 'app in (kafka-ui,kafka-manager,kafka-jmx-exporter)'
# 查看服务
kubectl get svc -n kafka-cluster
# 查看 Ingress
kubectl get ingress -n kafka-cluster

网络访问配置#
外部访问方案#
方案一:LoadBalancer 服务#
cat > kafka-external-access.yaml << 'EOF'
# Kafka 外部访问配置
apiVersion: v1
kind: Service
metadata:
name: kafka-external
namespace: kafka-cluster
spec:
type: LoadBalancer
ports:
- name: kafka
port: 9092
targetPort: 9092
protocol: TCP
selector:
app: cp-kafka
release: kafka-dev
---
# ZooKeeper 外部访问(谨慎使用)
apiVersion: v1
kind: Service
metadata:
name: zookeeper-external
namespace: kafka-cluster
spec:
type: LoadBalancer
ports:
- name: zookeeper
port: 2181
targetPort: 2181
protocol: TCP
selector:
app: cp-zookeeper
release: kafka-dev
EOF
kubectl apply -f kafka-external-access.yaml
方案二:NodePort 服务#
cat > kafka-nodeport.yaml << 'EOF'
apiVersion: v1
kind: Service
metadata:
name: kafka-nodeport
namespace: kafka-cluster
spec:
type: NodePort
ports:
- name: kafka
port: 9092
targetPort: 9092
nodePort: 30092
protocol: TCP
selector:
app: cp-kafka
release: kafka-dev
---
apiVersion: v1
kind: Service
metadata:
name: zookeeper-nodeport
namespace: kafka-cluster
spec:
type: NodePort
ports:
- name: zookeeper
port: 2181
targetPort: 2181
nodePort: 30181
protocol: TCP
selector:
app: cp-zookeeper
release: kafka-dev
EOF
kubectl apply -f kafka-nodeport.yaml
方案三:Ingress 配置(推荐)#
Nginx Ingress 配置#
cat > kafka-ingress-nginx.yaml << 'EOF'
apiVersion: networking.k8s.io/v1
kind: Ingress
metadata:
name: kafka-ingress
namespace: kafka-cluster
annotations:
kubernetes.io/ingress.class: "nginx"
nginx.ingress.kubernetes.io/ssl-redirect: "false"
nginx.ingress.kubernetes.io/backend-protocol: "HTTP"
spec:
rules:
- host: kafka.your-domain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kafka-ui
port:
number: 8080
- host: kafka-manager.your-domain.com
http:
paths:
- path: /
pathType: Prefix
backend:
service:
name: kafka-manager
port:
number: 9000
EOF
kubectl apply -f kafka-ingress-nginx.yaml
Traefik Ingress 配置#
cat > kafka-traefik-ingress.yaml << 'EOF'
# 创建认证密钥
apiVersion: v1
kind: Secret
metadata:
name: kafka-auth
namespace: kafka-cluster
type: Opaque
data:
users: YWRtaW46JGFwcjEkOHJjc2dCdE8kQS5zZnZ2a2JiUWljRlAyaHp2SzhELwoK # admin:password123
---
# BasicAuth 中间件
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: kafka-auth
namespace: kafka-cluster
spec:
basicAuth:
secret: kafka-auth
removeHeader: true
---
# 路径前缀处理中间件
apiVersion: traefik.containo.us/v1alpha1
kind: Middleware
metadata:
name: kafka-stripprefix
namespace: kafka-cluster
spec:
stripPrefix:
forceSlash: false
prefixes:
- /kafka
---
# Kafka UI 路由
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: kafka-ui-route
namespace: kafka-cluster
spec:
entryPoints:
- web
routes:
- match: Host(`kafka.your-domain.com`)
kind: Rule
services:
- name: kafka-ui
port: 8080
middlewares:
- name: kafka-auth
---
# Kafka Manager 路由
apiVersion: traefik.containo.us/v1alpha1
kind: IngressRoute
metadata:
name: kafka-manager-route
namespace: kafka-cluster
spec:
entryPoints:
- web
routes:
- match: Host(`kafka-manager.your-domain.com`)
kind: Rule
services:
- name: kafka-manager
port: 9000
middlewares:
- name: kafka-auth
EOF
kubectl apply -f kafka-traefik-ingress.yaml
客户端连接配置#
集群内部连接#
# Kafka Bootstrap Servers
KAFKA_BOOTSTRAP_SERVERS="kafka-dev-cp-kafka:9092"
# ZooKeeper 连接字符串
ZOOKEEPER_CONNECT="kafka-dev-cp-zookeeper:2181"
# Schema Registry URL
SCHEMA_REGISTRY_URL="http://kafka-dev-cp-schema-registry:8081"
集群外部连接#
# 通过 LoadBalancer
KAFKA_BOOTSTRAP_SERVERS="<EXTERNAL-IP>:9092"
# 通过 NodePort
KAFKA_BOOTSTRAP_SERVERS="<NODE-IP>:30092"
# 通过 Ingress(需要特殊配置)
# 注意:Kafka 协议通过 HTTP Ingress 需要特殊处理
连接测试脚本#
cat > test-kafka-connection.sh << 'EOF'
#!/bin/bash
KAFKA_POD=$(kubectl get pods -n kafka-cluster -l app=cp-kafka -o jsonpath='{.items[0].metadata.name}')
NAMESPACE="kafka-cluster"
echo "=== Kafka 连接测试 ==="
# 创建测试主题
echo "创建测试主题..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-topics \
--create \
--topic test-topic \
--bootstrap-server localhost:9092 \
--partitions 3 \
--replication-factor 1
# 列出主题
echo "列出所有主题..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-topics \
--list \
--bootstrap-server localhost:9092
# 发送测试消息
echo "发送测试消息..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- bash -c \
'echo "Hello Kafka from K8s!" | kafka-console-producer \
--topic test-topic \
--bootstrap-server localhost:9092'
# 消费测试消息
echo "消费测试消息..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-console-consumer \
--topic test-topic \
--bootstrap-server localhost:9092 \
--from-beginning \
--max-messages 1
# 删除测试主题
echo "删除测试主题..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-topics \
--delete \
--topic test-topic \
--bootstrap-server localhost:9092
echo "=== 连接测试完成 ==="
EOF
chmod +x test-kafka-connection.sh
./test-kafka-connection.sh
集群管理与使用#
Kafka UI 使用指南#
访问管理界面#
通过端口转发访问:
kubectl port-forward -n kafka-cluster svc/kafka-ui 8080:8080然后访问:
http://localhost:8080通过 Ingress 访问: 访问配置的域名:
http://kafka.your-domain.com
主要功能#
- 集群概览:查看集群状态、节点信息、主题统计
- 主题管理:创建、删除、配置主题
- 消息浏览:查看主题中的消息内容
- 消费者组管理:监控消费者组状态和消费进度
- 连接器管理:管理 Kafka Connect 连接器
- Schema 管理:管理 Schema Registry 中的模式
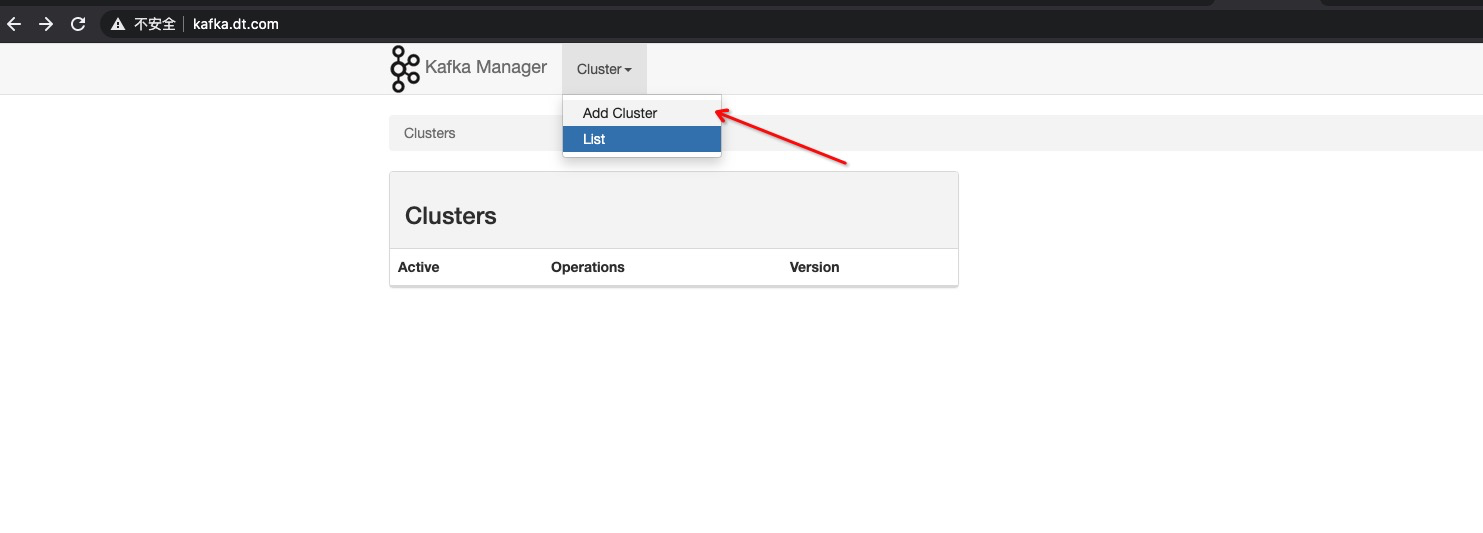
Kafka Manager 使用指南#
添加集群配置#
- 访问管理界面后,点击 “Add Cluster”
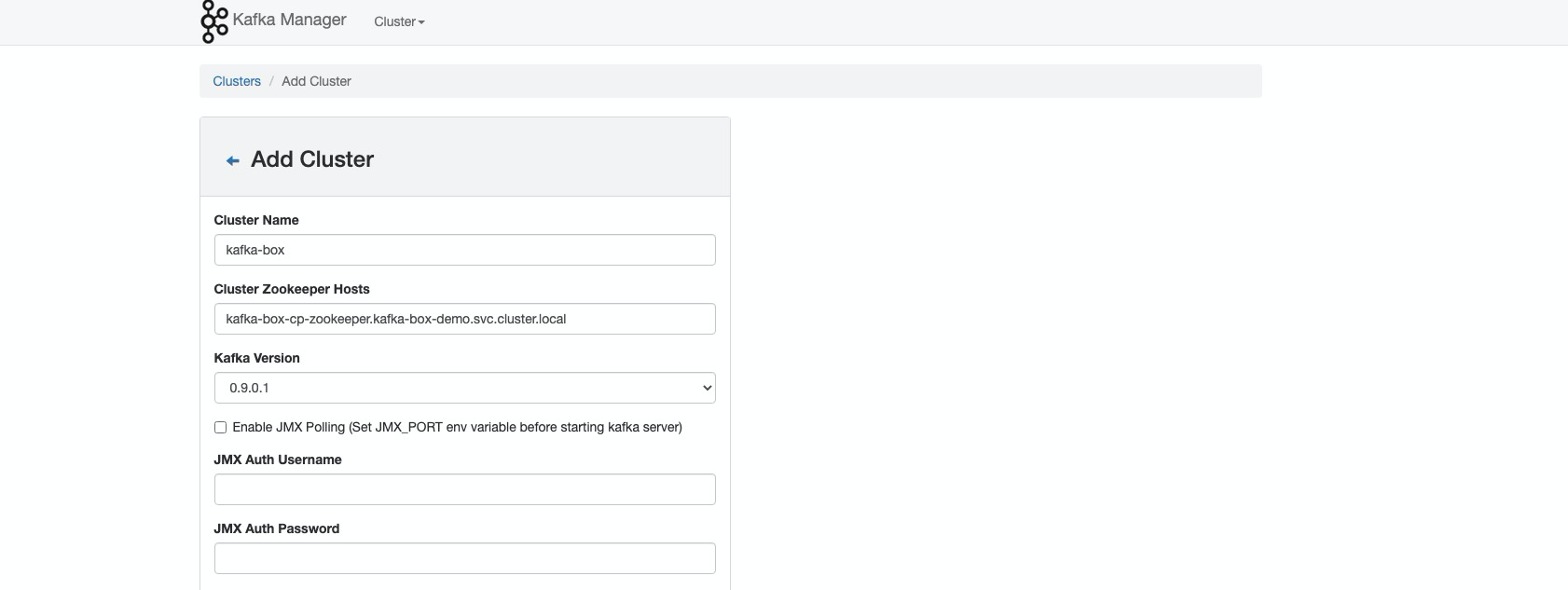
- 填写集群信息:
- Cluster Name:
kafka-cluster - Cluster Zookeeper Hosts:
kafka-dev-cp-zookeeper.kafka-cluster.svc.cluster.local:2181 - Kafka Version: 选择对应版本
- Enable JMX Polling: 勾选以启用监控
- Cluster Name:
- 高级配置:
- 启用 JMX 监控
- 配置安全认证(如需要)
- 设置消费者组监控
- 保存配置,集群添加完成
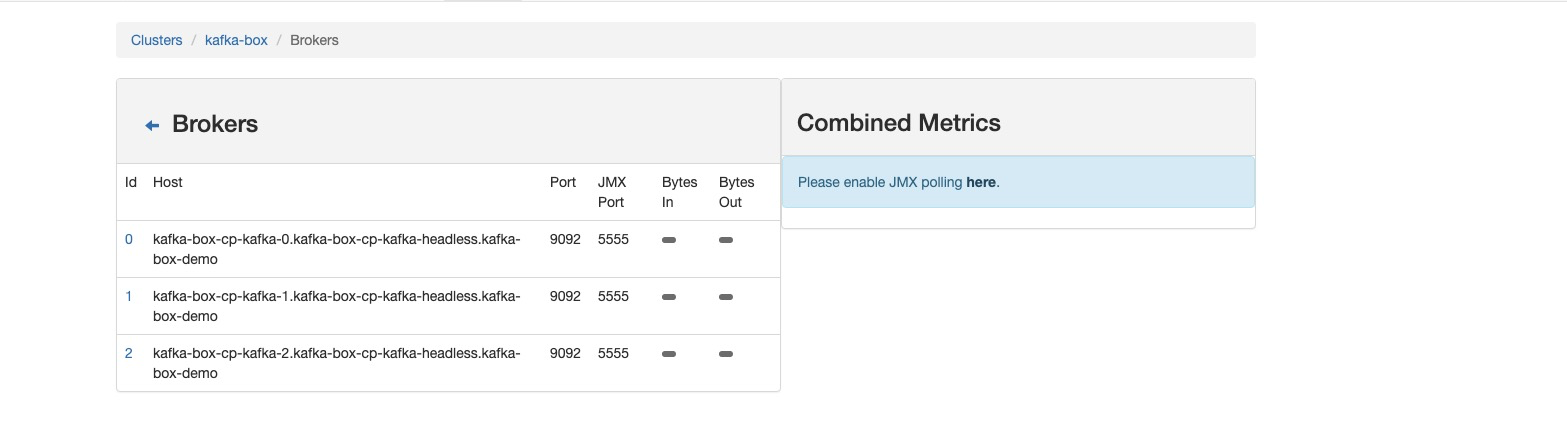
运维管理#
集群监控脚本#
cat > kafka-cluster-monitor.sh << 'EOF'
#!/bin/bash
NAMESPACE="kafka-cluster"
KAFKA_RELEASE="kafka-dev"
echo "=== Kafka 集群监控报告 ==="
echo "时间: $(date)"
echo
# 检查 Pod 状态
echo "=== Pod 状态 ==="
kubectl get pods -n $NAMESPACE -l release=$KAFKA_RELEASE
echo
echo "=== 服务状态 ==="
kubectl get svc -n $NAMESPACE -l release=$KAFKA_RELEASE
echo
echo "=== 持久化卷状态 ==="
kubectl get pvc -n $NAMESPACE
echo
echo "=== 资源使用情况 ==="
kubectl top pods -n $NAMESPACE 2>/dev/null || echo "metrics-server 未安装"
echo
echo "=== 集群健康检查 ==="
KAFKA_POD=$(kubectl get pods -n $NAMESPACE -l app=cp-kafka -o jsonpath='{.items[0].metadata.name}')
if [ -n "$KAFKA_POD" ]; then
echo "检查 Kafka 主题..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-topics \
--list \
--bootstrap-server localhost:9092 | head -10
echo
echo "检查消费者组..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-consumer-groups \
--list \
--bootstrap-server localhost:9092 | head -10
else
echo "未找到 Kafka Pod"
fi
echo
echo "=== 监控报告完成 ==="
EOF
chmod +x kafka-cluster-monitor.sh
备份与恢复#
cat > kafka-backup.sh << 'EOF'
#!/bin/bash
NAMESPACE="kafka-cluster"
BACKUP_DIR="/backup/kafka/$(date +%Y%m%d)"
KAFKA_POD=$(kubectl get pods -n $NAMESPACE -l app=cp-kafka -o jsonpath='{.items[0].metadata.name}')
mkdir -p $BACKUP_DIR
echo "=== Kafka 集群备份 ==="
# 备份主题配置
echo "备份主题配置..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-topics \
--describe \
--bootstrap-server localhost:9092 > $BACKUP_DIR/topics-config.txt
# 备份消费者组信息
echo "备份消费者组信息..."
kubectl exec -n $NAMESPACE $KAFKA_POD -- kafka-consumer-groups \
--describe \
--all-groups \
--bootstrap-server localhost:9092 > $BACKUP_DIR/consumer-groups.txt
# 备份 Kubernetes 资源
echo "备份 Kubernetes 资源..."
kubectl get all -n $NAMESPACE -o yaml > $BACKUP_DIR/k8s-resources.yaml
kubectl get pvc -n $NAMESPACE -o yaml > $BACKUP_DIR/pvc-resources.yaml
kubectl get configmap -n $NAMESPACE -o yaml > $BACKUP_DIR/configmap-resources.yaml
echo "备份完成,文件保存在: $BACKUP_DIR"
EOF
chmod +x kafka-backup.sh
性能调优#
cat > kafka-performance-tuning.yaml << 'EOF'
# Kafka 性能调优配置
cp-kafka:
configurationOverrides:
# 网络和 I/O 优化
"num.network.threads": "16"
"num.io.threads": "32"
"socket.send.buffer.bytes": "102400"
"socket.receive.buffer.bytes": "102400"
"socket.request.max.bytes": "104857600"
# 日志优化
"log.flush.interval.messages": "10000"
"log.flush.interval.ms": "1000"
"log.segment.bytes": "1073741824"
"log.retention.check.interval.ms": "300000"
# 压缩优化
"compression.type": "lz4"
"log.cleanup.policy": "delete"
# 副本优化
"replica.fetch.max.bytes": "1048576"
"replica.socket.receive.buffer.bytes": "65536"
# 生产者优化
"batch.size": "16384"
"linger.ms": "5"
"buffer.memory": "33554432"
# JVM 优化
heapOptions: "-Xms6G -Xmx6G -XX:+UseG1GC -XX:MaxGCPauseMillis=20 -XX:InitiatingHeapOccupancyPercent=35"
EOF
故障排除#
常见问题#
1. Pod 启动失败#
问题现象:Pod 处于 Pending 或 CrashLoopBackOff 状态
排查步骤:
# 查看 Pod 详细信息
kubectl describe pod <pod-name> -n kafka-cluster
# 查看 Pod 日志
kubectl logs <pod-name> -n kafka-cluster
# 检查资源限制
kubectl get nodes
kubectl describe node <node-name>
常见原因:
- 资源不足(CPU、内存、存储)
- 存储类不可用
- 镜像拉取失败
- 配置错误
2. 存储问题#
问题现象:PVC 处于 Pending 状态
排查步骤:
# 查看 PVC 状态
kubectl get pvc -n kafka-cluster
# 查看存储类
kubectl get storageclass
# 查看 PV
kubectl get pv
解决方案:
- 确认存储类配置正确
- 检查存储提供商状态
- 验证存储容量是否足够
3. 网络连接问题#
问题现象:服务间无法通信
排查步骤:
# 测试服务连通性
kubectl exec -n kafka-cluster <kafka-pod> -- nc -zv <zookeeper-service> 2181
# 查看服务端点
kubectl get endpoints -n kafka-cluster
# 检查网络策略
kubectl get networkpolicy -n kafka-cluster
4. 性能问题#
问题现象:消息处理延迟高
排查步骤:
# 查看资源使用
kubectl top pods -n kafka-cluster
# 检查 JVM 参数
kubectl exec -n kafka-cluster <kafka-pod> -- ps aux | grep java
# 查看 Kafka 指标
kubectl port-forward -n kafka-cluster svc/kafka-jmx-exporter 5556:5556
curl http://localhost:5556/metrics
总结#
部署优势#
通过本指南,您可以在 Kubernetes 中成功部署一个企业级的 Kafka 集群,具有以下优势:
技术优势#
- 高可用性:多节点部署,支持故障自动恢复
- 可扩展性:支持水平扩展,满足业务增长需求
- 持久化存储:数据安全可靠,支持备份恢复
- 监控完善:集成监控和管理工具,运维便捷
运维优势#
- 容器化部署:标准化部署流程,环境一致性好
- 自动化管理:Kubernetes 自动处理容器生命周期
- 资源隔离:命名空间和资源限制保证系统稳定
- 版本管理:Helm Charts 支持版本控制和回滚
最佳实践#
生产环境建议#
- 资源规划:根据业务需求合理规划 CPU、内存和存储
- 安全配置:启用认证、授权和网络策略
- 监控告警:部署完整的监控和告警体系
- 备份策略:制定定期备份和灾难恢复计划
- 性能调优:根据业务特点调整 Kafka 配置参数
扩展建议#
- 多集群部署:考虑跨区域的多集群架构
- 数据治理:实施 Schema Registry 和数据质量管控
- 流处理集成:集成 Kafka Streams 或 Apache Flink
- 安全加固:实施端到端加密和细粒度权限控制
外部连接解决方案#
针对原文提到的外部连接问题,现代的解决方案包括:
- Strimzi Operator:专门为 Kubernetes 设计的 Kafka 操作器
- Confluent Operator:Confluent 官方的 Kubernetes 操作器
- 自定义网络配置:通过 advertised.listeners 配置外部访问
- Service Mesh:使用 Istio 等服务网格解决网络问题
通过本指南的配置和最佳实践,您可以构建一个稳定、高效、可扩展的 Kafka 流处理平台,为企业的数据处理和实时分析提供强有力的支撑。