
故障时间线#
先用一张图说明整件事的来龙去脉:
flowchart TD
A[早晨监控告警
IPv6 地址丢失] --> B{登机排查
curl 6.ipw.cn 失败}
B --> C[误判为 DHCPv6 续约失败]
C --> D[在 pfSense 上执行 reboot]
D --> E[全屋断网
钉钉告警全无]
E --> F[赶到公司接显示器]
F --> G[EFI loader 报错
Failed to find bootable partition]
G --> H[启动 U 盘 ZFS 文件系统崩盘]
H --> I[用备用 SSD 重装 pfSense
放弃 ZFS 改用 UFS]
I --> J[通过 restic 异地备份恢复配置]
J --> K[IPv6 仍异常
发现是 ipw.cn 服务问题]
K --> L[自建 IPv6 查询服务
并修改 DDNS 数据源]
L --> M[故障收敛]
一、故障缘由:一次看似普通的 IPv6 告警#
早上监控系统弹出告警,提示某台机器的 IPv6 地址丢失。登上机器确认:
root@ipv6-dmz-lb-110-110:~# curl https://6.ipw.cn
curl: (6) Could not resolve host: 6.ipw.cn
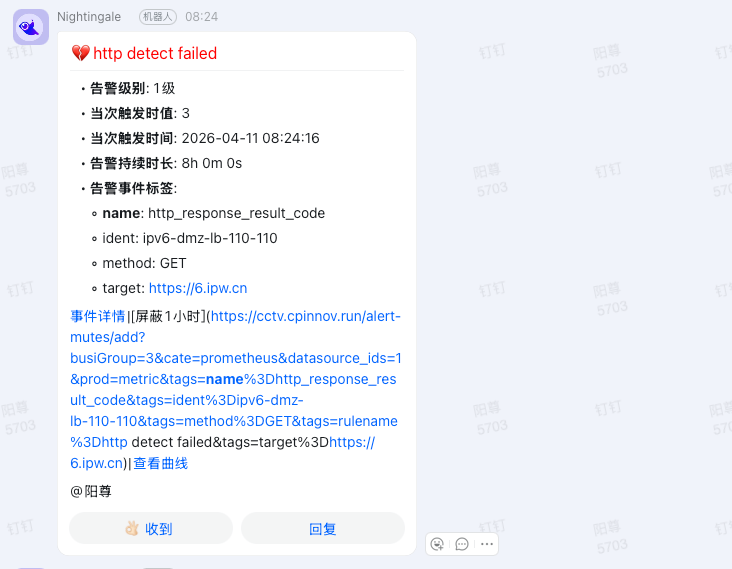
按以往经验,这类问题多半是上级防火墙的 DHCPv6 续约失败(运营商分配的 IPv6 前缀会定期变更)。我平时用来检测 IPv6 连通性的站点是 https://ipw.cn/ipv6/。
登上防火墙一看,IPv6 地址其实是有的,但同样请求 6.ipw.cn 依然失败。我一拍脑袋判断是续租分配有问题,直接执行了 reboot——然后噩梦开始了。
重启之后,家里的远程服务器全部失联,钉钉告警消息一条都收不到。这才意识到:防火墙起不来了。
事后复盘:其实是 ipw.cn 这个第三方站点当时服务异常 + pfSense 的 U 盘磁盘本身处于亚健康状态,两个独立问题叠加,在重启的一瞬间集中爆发。
ping6 www.baidu.com 其实是通的,只是 curl 6.ipw.cn 解析失败:
root@ipv6-dmz-lb-110-110:~# ping6 www.baidu.com
PING www.baidu.com(240e:ff:e020:99b:0:ff:b099:cff1) 56 data bytes
64 bytes from ...: icmp_seq=1 ttl=54 time=5.91 ms
64 bytes from ...: icmp_seq=2 ttl=54 time=6.06 ms
--- www.baidu.com ping statistics ---
2 packets transmitted, 2 received, 0% packet loss
root@ipv6-dmz-lb-110-110:~# curl https://6.ipw.cn
curl: (6) Could not resolve host: 6.ipw.cn
如果当时稍微多做一步 ping6 验证,就不会贸然重启。
二、定位问题:Failed to find bootable partition#
刷牙洗脸赶到公司,给防火墙接上显示器,屏幕停留在这样的画面:
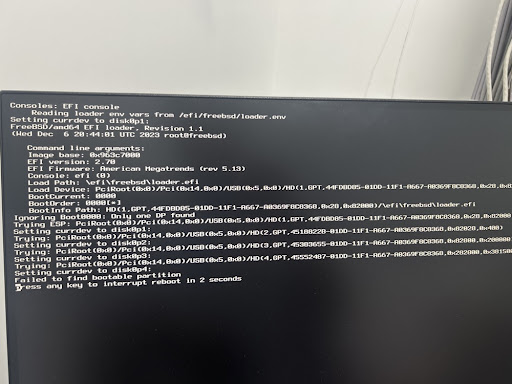
核心错误信息:
FreeBSD/amd64 EFI loader
...
USB(0x5,0x0)/...
...
Failed to find bootable partition
把截图甩给 Gemini 分析,结论也很清晰:
- 系统环境:FreeBSD/amd64 EFI loader,这台机器是 pfSense;
- 启动介质:路径里出现
USB(0x5,0x0),说明系统正从 U 盘启动;- 故障点:UEFI 识别到了 U 盘,EFI 引导程序也加载了,但依次尝试
disk0p1~disk0p4全部失败——引导能读到,但系统主分区已经挂掉。
最可能的根因:普通 U 盘的闪存颗粒不适合长期作为系统盘频繁读写,更何况这台机器上跑的还是对写入极为敏感的 ZFS。
三、重装 pfSense:没网的时候怎么装需要联网的系统?#
手头刚好有一块备用的 SATA SSD,准备直接重装。结果又撞上两堵墙:
问题 1:官方镜像依赖联网安装#
从 pfSense 官网下载的最新镜像,在安装过程中会去拉远端包仓库。但此时:
- 主 WAN 接在 pfSense 上,而 pfSense 已经挂了,所以笔记本没网;
- 备用 WAN 接在 FortiGate 上,有网,但我笔记本没直连过去。
最后只能把笔记本连到手机热点上查资料,找到 Netgate 官方镜像站:
问题 2:镜像下载极慢#
这个镜像站在国内裸连几乎跑不动。临时方案是用异地 VPS 做中转:
flowchart LR
A[Netgate 镜像站
atxfiles.netgate.com] -->|wget 高速直连| B[香港/新加坡 VPS]
B -->|scp 回内网| C[我的笔记本]
C -->|写入 U 盘| D[新的 pfSense 安装盘]
手里有香港和新加坡各一台 VPS,先在 VPS 上下载(海外速度非常快),再从 VPS scp 回本地,整体耗时比裸连直接下降一个数量级。
问题 3:文件系统选择——这次坚决不用 ZFS#
安装时 pfSense 会让你选择文件系统。上一次我选的是 ZFS,也正是这次翻车的主要嫌疑人:
为什么 ZFS 在这台机器上不合适?
- 这是一台普通 PC(没有 ECC 内存)+ Intel 四口网卡的软路由;
- ZFS 设计上依赖 ECC 来对抗内存位翻转,在非 ECC 环境下反而可能加速数据损坏;
- ZFS 的写放大 + 元数据频繁更新,会让低端 U 盘 / 廉价 SSD 的寿命大幅缩水;
- 上一块 SATA SSD 用了 ZFS 大约 1 年写爆,这次的 U 盘只扛了几个月。
这次我果断选择了 UFS(Auto - ZFS 的那个选项换成非 ZFS),安装过程更像 DD,直接把系统镜像写到盘上,装完开机即可用。
四、恢复配置:从 restic 异地备份中捞回 XML#
pfSense 装好了,但还是一台光秃秃的新机器——所有 NAT 规则、VPN、VLAN、DHCP 映射都需要从备份恢复。
预案起了作用:独立于防火墙的异地备份#
我的备份方案是 pfSense 定期把 config.xml 推送到 restic-rest-server,每 4 小时一次。关键决策是:
经验教训 2:异地备份服务必须部署在防火墙故障时你仍能访问的网络里。
我当时专门把 restic-rest-server 部署在一个特殊的局域网下。防火墙挂掉后,我依然能通过另一条路径连到这台备份服务器——这是整个故障中最救命的一步预案。
忘记的密码:重置 htpasswd#
连上备份服务器后发现自己忘了 restic-rest 的 HTTP Basic Auth 密码。好在服务是 Docker 部署,直接 exec 进去重置:
root@5600x:/nvme1n1p1/docker-compose/restic-rest-server# \
docker exec -it restic-rest-server htpasswd -B /data/.htpasswd pfsense-backup
New password:
Re-type new password:
Updating password for user pfsense-backup
临时把密码改成了 123456(事后记得改回强密码)。
忘记的密码 Part 2:restic 仓库加密密钥#
restic 本身对仓库有独立的加密密钥,这个密钥在初始化仓库时设置,一旦丢失就真的拿不到数据了。
一顿乱翻之后,在 docker-compose.yml 同级目录发现了一个自己当初写的清理脚本 prune.sh——这个脚本用来定期 forget 旧快照,里面硬编码了 RESTIC_PASSWORD:
root@5600x:/nvme1n1p1/docker-compose/restic-rest-server# tree -L 2
.
├── data
│ └── pfsense
├── docker-compose.yml
└── prune.sh
#!/bin/bash
# restic 仓库定期清理脚本(服务端执行)
# 配合 --append-only 模式使用
set -e
RESTIC_REPO="/data/pfsense"
RESTIC_PASS="xxxx" # <-- 就是这个,救了我一命
echo "=== $(date) 开始清理 restic 仓库 ==="
docker run --rm \
-v "/nvme1n1p1/docker-compose/restic-rest-server/data/pfsense:/repo" \
-e RESTIC_REPOSITORY="/repo" \
-e RESTIC_PASSWORD="$RESTIC_PASS" \
restic/restic:latest forget \
--keep-daily 30 \
--keep-weekly 8 \
--keep-monthly 12 \
--prune 2>&1
这是个双刃剑的教训:
- 好的一面:密钥写在脚本里,紧急情况下救了我;
- 坏的一面:密钥明文存放在同一台服务器上,如果这台服务器本身被入侵,加密就形同虚设。
更好的做法是把 restic password 放到 1Password / Bitwarden / Vault 里,同时在本地留一份离线纸质备份。
拉取备份并恢复#
拿到密钥后,先列出快照,再按 ID 恢复:
# 列出所有快照
restic -r rest:http://pfsense-backup:123456@10.16.110.17:8100/pfsense snapshots
# 恢复指定快照到本地目录
restic -r rest:http://pfsense-backup:123456@10.16.110.17:8100/pfsense \
restore b590bfab --target /tmp/pfsense_backup_1_b590bfab
我一口气拉了最近 5 个快照以防某一个文件坏掉:

然后笔记本直连 pfSense 的 LAN 口,自动获取 DHCP,访问网关 Web UI,在 Diagnostics - Backup & Restore 页面上传 XML,一键全量恢复。内网瞬间满血复活。
五、顺便解决根因:自建 IPv6 查询服务#
恢复之后再次到业务机器上 curl 6.ipw.cn,依然失败。这一次我没有再盲目重启,而是交叉验证了一下:
ping6 www.baidu.com # 正常
curl -6 ifconfig.co # 正常
curl https://6.ipw.cn # DNS 解析失败
根因水落石出:ipw.cn 的 IPv6 查询服务本身在抽风。 原来的告警是误报,只是我用它来做 IPv6 可用性判断,导致监控系统以为我没有 IPv6。
治本方案:别再依赖第三方服务。让 Claude Code 帮我写了一个极简的 IPv6 查询服务,部署到自己的机器上。已经开源:
对外暴露的地址:
# 自动识别(客户端用 v4 就返回 v4,用 v6 就返回 v6)
curl http://42.194.147.52:8080/
# 强制 IPv6
curl -6 http://[2402:4e00:c011:2000:9c:aba0:785a:0]:8080/
配置完后再把 DDNS 里用来获取 IPv6 的数据源地址也换成这个自建服务,整条链路就完全掌握在自己手里了:
六、复盘与教训#
这次事故从告警到恢复,前后花了大半个上午。写在最后,是几条我想烙在脑子里的经验:
教训 1:不要在生产系统上盲目重启#
“重启大法好” 在个人电脑上成立,在生产系统上是一句非常危险的话。
很多平时没有暴露的问题(磁盘坏块、内存坏块、未 flush 的配置、systemd 启动顺序问题),都会在重启的那一瞬间被一次性引爆。重启前至少先确认:一旦起不来,你有没有办法把它救回来。
教训 2:不要在 U 盘上跑 ZFS(尤其是没有 ECC 的机器)#
- pfSense 已经连续两次因为 ZFS 把我的存储写爆:
- 上一次是一块 SATA SSD,扛了一年多;
- 这一次是临时应急的 U 盘,只扛了几个月;
- 普通 PC 没有 ECC 内存,ZFS 的优势(数据完整性校验)反而是一种负担;
- 这次重装我已经改用 UFS,后续观察寿命表现。
教训 3:备份服务一定要放在"故障域之外"#
这次能快速恢复的关键,是我当初把 restic-rest-server 部署在一个不经过 pfSense 就能访问的网络里。如果备份服务藏在 pfSense 后面,这次就只能含泪从零开始重配所有规则了。
自检问题:你的备份系统,在你的防火墙 / 主路由挂掉时还能访问吗?
教训 4:密钥管理需要"多级冗余"#
- 服务密码可以随时
htpasswd重置,这没问题; - 但 restic 的仓库加密密钥一旦丢失就是毁灭性的;
- 这次靠
prune.sh脚本里的明文密码救了命,但这不是一个安全的长期方案; - 改进:密钥存 1Password + 一份离线打印件 + 关键运维脚本里可以保留但要做好访问控制。
教训 5:关键依赖不要放在第三方免费服务上#
整件事的导火索,其实是 ipw.cn 这个第三方 IPv6 查询站点抽风。监控系统依赖它来判断 IPv6 可用性,它一挂就会触发假告警。自建一个 10 行代码的服务,就可以一劳永逸地解决。
七、下一步改进#
基于这次教训,后续会做以下完善:
- 制作离线 pfSense 安装介质:预先下载好 ISO 并保存到 NAS,避免"防火墙挂掉才发现镜像下不下来"的死循环;
- 运维手册(Runbook):把 restic 恢复命令、备份地址、密钥位置写成一份加密文档,放到 1Password;
- 监控加 Fallback 判断:IPv6 可用性检测同时查
自建服务 + ping6 + 第三方,任意一个通过就不告警; - Infrastructure as Code:pfSense 配置除了 XML 备份之外,再用 Ansible / pfsense-api 做一份"人类可读"的版本化配置。
目标:下次再出现类似事故,从告警到完全恢复,能压缩到 30 分钟以内。
这次踩坑就当作一次真实的灾难演练。运维最宝贵的不是从不翻车,而是每翻一次车都能让下次的 MTTR(平均恢复时间)更短一点。