
环境配置#
- Kubernetes 版本:v1.20.4 (KubeKey 部署)
- 操作系统:CentOS 7.9.2009
- Rancher 版本:v2.4.15
准备 Kubernetes 测试环境#
本次使用 KubeKey 进行一键部署。KubeKey 底层集群部署基于 kubeadm,详细信息可参考 GitHub 地址。
编译安装 KubeKey#
系统初始化步骤省略,编译时需要使用 Docker 容器,请事先安装。系统初始化步骤可参考文档
yum install -y git
git clone https://github.com/kubesphere/kubekey.git \
&& cd kubekey
./build.sh -p # 执行编译,如需交叉编译,需要在脚本中添加对应环境变量
cp -a output/kk /usr/local/bin/
kk version # 如输出以下信息,则表示安装成功
version.BuildInfo{Version:"latest+unreleased", GitCommit:"f3f9e2e2d001a1b35883f5baea07912bb636db56", GitTreeState:"clean", GoVersion:"go1.14.7"}
部署集群#
mkdir -p ~/kubekey-workspace
kk create config --with-kubernetes v1.20.4 # 生成配置文件
cat config-sample.yaml
apiVersion: kubekey.kubesphere.io/v1alpha1
kind: Cluster
metadata:
name: sample
spec:
hosts:
- {name: node1, address: 192.168.8.70, internalAddress: 192.168.8.70, user: root, password: 123456}
- {name: node2, address: 192.168.8.71, internalAddress: 192.168.8.71, user: root, password: 123456}
roleGroups:
etcd:
- node1
master:
- node1
worker:
- node1
- node2
controlPlaneEndpoint:
domain: lb.kubesphere.local
address: ""
port: 6443
kubernetes:
version: v1.20.4
imageRepo: kubesphere
clusterName: cluster.local
network:
plugin: calico
kubePodsCIDR: 10.233.64.0/18
kubeServiceCIDR: 10.233.0.0/18
registry:
registryMirrors: []
insecureRegistries: []
addons: []
yum install socat conntrack -y # 安装依赖
kk create cluster -f ./config-sample.yaml # 创建集群
+-------+------+------+---------+----------+-------+-------+-----------+---------+------------+-------------+------------------+--------------+
| name | sudo | curl | openssl | ebtables | socat | ipset | conntrack | docker | nfs client | ceph client | glusterfs client | time |
+-------+------+------+---------+----------+-------+-------+-----------+---------+------------+-------------+------------------+--------------+
| node2 | y | y | y | y | y | y | y | 20.10.7 | | | | CST 09:39:04 |
| node1 | y | y | y | y | y | y | y | 20.10.7 | | | | CST 09:39:04 |
+-------+------+------+---------+----------+-------+-------+-----------+---------+------------+-------------+------------------+--------------+
This is a simple check of your environment.
Before installation, you should ensure that your machines meet all requirements specified at
https://github.com/kubesphere/kubekey#requirements-and-recommendations
Continue this installation? [yes/no]: yes # 输入 yes
Rancher 导入集群#
导入步骤省略。问题现象如下:Dashboard 界面提示 Scheduler 和 Controller Manager 组件不健康。
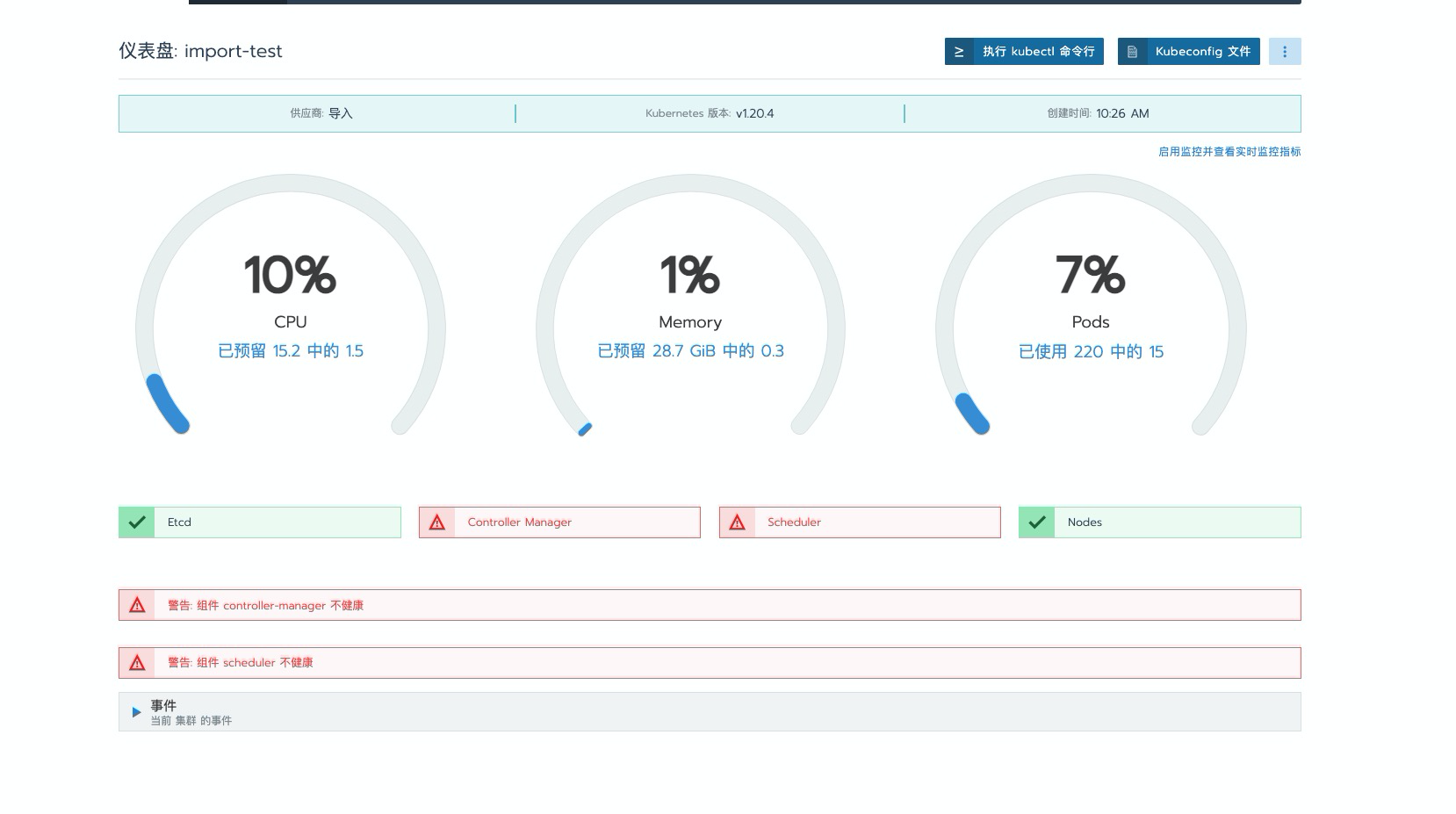
通过命令行查看组件状态:
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
scheduler Unhealthy Get "http://127.0.0.1:10251/healthz": dial tcp 127.0.0.1:10251: connect: connection refused
controller-manager Unhealthy Get "http://127.0.0.1:10252/healthz": dial tcp 127.0.0.1:10252: connect: connection refused
etcd-0 Healthy {"health":"true"}
问题分析与修复#
问题原因#
在较新版本的 kubeadm 部署的集群中,默认关闭了 HTTP 通信端口,导致健康检查时无法通信,自检失败。
解决方案#
目前有两种解决思路:
- 方案一:将自检调用的端口更改为 HTTPS
- 方案二:重新启用 HTTP 端口监听
本文介绍较为简单的方案二进行修复。
安全提示:此方法存在一定的安全风险,请根据实际环境评估使用。
修复 HTTP 端口监听#
由于使用 kubeadm 部署集群,只需修改对应的静态 Pod YAML 文件配置即可。
修复 Scheduler 组件#
vi /etc/kubernetes/manifests/kube-scheduler.yaml # 编辑 Scheduler 配置文件
...
spec:
containers:
- command:
- kube-scheduler
- --authentication-kubeconfig=/etc/kubernetes/scheduler.conf
- --authorization-kubeconfig=/etc/kubernetes/scheduler.conf
- --bind-address=0.0.0.0
- --feature-gates=CSINodeInfo=true,VolumeSnapshotDataSource=true,ExpandCSIVolumes=true,RotateKubeletClientCertificate=true,RotateKubeletServerCertificate=true
- --kubeconfig=/etc/kubernetes/scheduler.conf
- --leader-elect=true
# - --port=0 # 将此行注释掉
...
### 修复 Controller Manager 组件
```bash
vi /etc/kubernetes/manifests/kube-controller-manager.yaml # 编辑 Controller Manager 配置文件
...
spec:
containers:
- command:
- kube-controller-manager
- --allocate-node-cidrs=true
- --authentication-kubeconfig=/etc/kubernetes/controller-manager.conf
- --authorization-kubeconfig=/etc/kubernetes/controller-manager.conf
- --bind-address=0.0.0.0
- --client-ca-file=/etc/kubernetes/pki/ca.crt
- --cluster-cidr=10.233.64.0/18
- --cluster-name=cluster.local
- --cluster-signing-cert-file=/etc/kubernetes/pki/ca.crt
- --cluster-signing-key-file=/etc/kubernetes/pki/ca.key
- --controllers=*,bootstrapsigner,tokencleaner
- --experimental-cluster-signing-duration=87600h
- --feature-gates=CSINodeInfo=true,VolumeSnapshotDataSource=true,ExpandCSIVolumes=true,RotateKubeletServerCertificate=true
- --kubeconfig=/etc/kubernetes/controller-manager.conf
- --leader-elect=true
- --node-cidr-mask-size=24
## - --port=0 # 将此行注释掉
...
快速修复方法#
也可以使用 sed 命令一键修复:
sed -i 's/.*--port=0.*/#&/' /etc/kubernetes/manifests/kube-controller-manager.yaml
sed -i 's/.*--port=0.*/#&/' /etc/kubernetes/manifests/kube-scheduler.yaml
验证修复结果#
修复完成后,再次查看 Dashboard 界面,可以看到错误提示已消失:
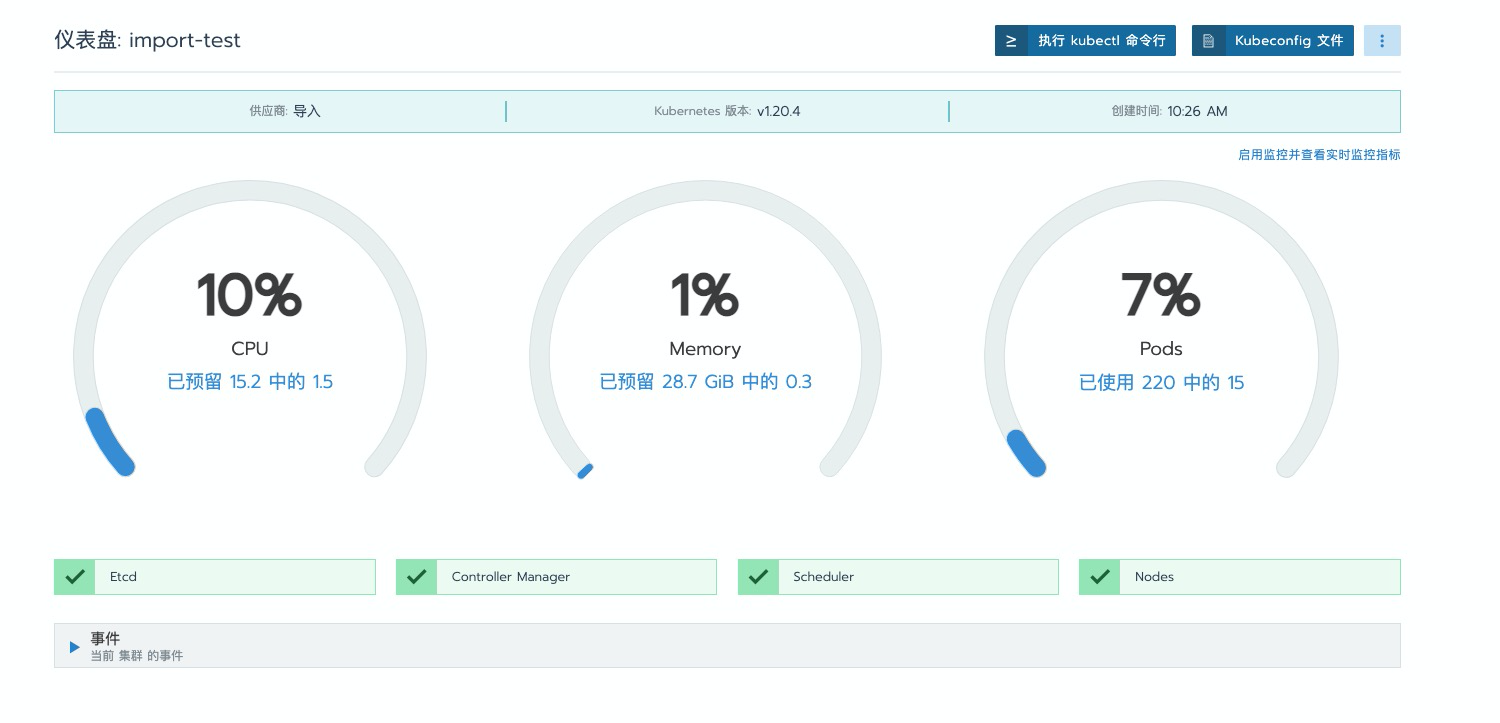
通过命令行验证组件状态:
kubectl get cs
Warning: v1 ComponentStatus is deprecated in v1.19+
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-0 Healthy {"health":"true"}
可以看到 Scheduler 和 Controller Manager 组件状态已恢复为 Healthy。