
背景#
Kube-Vip最初是为 Kubernetes 控制平面提供 HA 解决方案而创建的,随着时间的推移,它已经发展为将相同的功能合并到 Kubernetes 的 LoadBalancer 类型的 Service 中。Kube-Vip特点如下:
- VIP 地址可以是 IPv4 或 IPv6
- 带有 ARP(第2层)或 BGP(第3层)的控制平面
- 使用领导选举或
raft控制平面- 带有 kubeadm(静态 Pod)的控制平面 HA
- 带有 K3s/和其他(DaemonSets)的控制平面 HA
- 使用 ARP 领导者选举的 Service LoadBalancer(第 2 层)
- 通过 BGP 使用多个节点的 Service LoadBalancer
- 每个命名空间或全局的 Service LoadBalancer 地址池
- Service LoadBalancer 地址通过 UPNP 暴露给网关
集群 master 节点一般不会很多,kube-vip 只需在 k8s 中的控制平面部署。这里使用方法采用 静态 pod + ARP 来简单实现。在大规模的场景下可以尝试使用 BGP ,这需要相应的 BGP 服务来做支撑。
集群角色说明#
| IP地址 | 主机名称 | 集群角色 |
|---|---|---|
| 192.168.66.90 | master01 | controlplane、worker、etcd、kube-vip |
| 192.168.66.91 | master02 | controlplane、worker、etcd、kube-vip |
| 192.168.66.92 | master03 | controlplane、worker、etcd、kube-vip |
| 192.168.66.93 | node01 | worker |
| 192.168.66.101 | kube-vip.treesir.pub | kube-vip 虚拟 ip 地址 |
使用 RKE 部署集群#
部署前各主机的优化工作#
节点初始化,基础优化
更改主机名称,(
各节点执行)hostnamectl set-hostname xxxx将各主机名称写入至各
/etc/hosts文件中 (各节点执行)echo "192.168.66.90 master01 192.168.66.91 master02 192.168.66.92 master03 192.168.66.93 node01" >> /etc/hosts安装
rke&kubectl(主控节点执行)wget -O /usr/local/bin/rke https://github.com/rancher/rke/releases/download/v1.3.1/rke_linux-amd64 wget -O /usr/local/bin/kubectl "https://dl.k8s.io/release/`curl -L -s https://dl.k8s.io/release/stable.txt`/bin/linux/amd64/kubectl" chmod a+x /usr/local/bin/* # 添加可执行权限rke 集群所需用户 (
各节点执行)因 Centos/Redhat 发行版本下,rke 不支持使用
rook,这里需要单独创建一个 rke 用户,并加入至 docker 组,让其可以执行 docker 命令。useradd rke -G docker echo '123456'|passwd rke --stdin # 初始化 rke 用户密码为 123456配置 rke 支持使用免密钥管理(
主控节点执行)yum install -y sshpass su - rke # 切换至 rke 用户,生成公私钥 ssh-keygen # 一路回车,生成 for i in `seq 1 3`;do sshpass -p '123456' ssh-copy-id -o StrictHostKeyChecking=no master0"$i";done \ && sshpass -p '123456' ssh-copy-id -o StrictHostKeyChecking=no node01配置 kubectl 命令补全功能(
主控节点执行)echo 'source <(kubectl completion bash)' >> /etc/profile source /etc/profile
部署 rke 集群#
创建存放 静态 pod 文件夹
/etc/kubernetes/manifest/;(各节点执行)mkdir -p /etc/kubernetes/manifest/创建 rke 集群配置文件 (
主控节点执行)在
192.168.66.90节点中切换至rke用户,生成集群描述配置文件cluster.yml。#### #### RKE Kubernetes 安装模板 #### nodes: # master01 配置 - address: 192.168.66.90 user: rke role: - controlplane - etcd - worker ssh_key_path: ~/.ssh/id_rsa hostname_override: master01 port: 22 # master02 配置 - address: 192.168.66.91 user: rke role: - worker - etcd - controlplane ssh_key_path: ~/.ssh/id_rsa hostname_override: master02 port: 22 # master03 配置 - address: 192.168.66.92 user: rke role: - worker - etcd - controlplane hostname_override: master03 ssh_key_path: ~/.ssh/id_rsa # node01 配置 - address: 192.168.66.93 user: rke role: - worker ssh_key_path: ~/.ssh/id_rsa hostname_override: node01 port: 22 kubernetes_version: v1.21.5-rancher1-1 # 私有仓库 ## 当设置`is_default: true`后,构建集群时会自动在配置的私有仓库中拉取镜像 ## 如果使用的是DockerHub镜像仓库,则可以省略`url`或将其设置为`docker.io` ## 如果使用内部公开仓库,则可以不用设置用户名和密码 private_registries: - url: idocker.io user: admin password: 123456 is_default: true services: etcd: # 开启自动备份 ## rke版本小于0.2.x或rancher版本小于v2.2.0时使用 snapshot: true creation: 5m0s retention: 24h # 扩展参数 extra_args: auto-compaction-retention: 240 #(单位小时) quota-backend-bytes: '6442450944' kube-api: # cluster_ip范围 ## 这必须与kube-controller中的service_cluster_ip_range匹配 service_cluster_ip_range: 10.43.0.0/16 # NodePort映射的端口范围 service_node_port_range: 30000-32767 # Pod安全策略 pod_security_policy: false # kubernetes API server扩展参数 ## 这些参数将会替换默认值 extra_args: watch-cache: true default-watch-cache-size: 1500 # 事件保留时间,默认1小时 event-ttl: 1h0m0s # 默认值400,设置0为不限制,一般来说,每25~30个Pod有15个并行 max-requests-inflight: 800 # 默认值200,设置0为不限制 max-mutating-requests-inflight: 400 # kubelet操作超时,默认5s kubelet-timeout: 5s # 启用审计日志到标准输出 audit-log-path: "-" # 增加删除workers的数量 delete-collection-workers: 3 # 将日志输出的级别设置为debug模式 v: 4 # Rancher 2用户注意事项:如果在创建Rancher Launched Kubernetes时使用配置文件配置集群,则`kube_controller`服务名称应仅包含下划线。这仅适用于Rancher v2.0.5和v2.0.6。 kube-controller: # Pods_ip范围 cluster_cidr: 10.42.0.0/16 # cluster_ip范围 ## 这必须与kube-api中的service_cluster_ip_range相同 service_cluster_ip_range: 10.43.0.0/16 extra_args: # 修改每个节点子网大小(cidr掩码长度),默认为24,可用IP为254个;23,可用IP为510个;22,可用IP为1022个; node-cidr-mask-size: '22' # 控制器定时与节点通信以检查通信是否正常,周期默认5s node-monitor-period: '5s' ## 当节点通信失败后,再等一段时间kubernetes判定节点为notready状态。 ## 这个时间段必须是kubelet的nodeStatusUpdateFrequency(默认10s)的整数倍, ## 其中N表示允许kubelet同步节点状态的重试次数,默认40s。 node-monitor-grace-period: '20s' ## 再持续通信失败一段时间后,kubernetes判定节点为unhealthy状态,默认1m0s。 node-startup-grace-period: '30s' ## 再持续失联一段时间,kubernetes开始迁移失联节点的Pod,默认5m0s。 pod-eviction-timeout: '1m' # 默认5. 同时同步的deployment的数量。 concurrent-deployment-syncs: 5 # 默认5. 同时同步的endpoint的数量。 concurrent-endpoint-syncs: 5 # 默认20. 同时同步的垃圾收集器工作器的数量。 concurrent-gc-syncs: 20 # 默认10. 同时同步的命名空间的数量。 concurrent-namespace-syncs: 10 # 默认5. 同时同步的副本集的数量。 concurrent-replicaset-syncs: 5 # 默认5m0s. 同时同步的资源配额数。(新版本中已弃用) # concurrent-resource-quota-syncs: 5m0s # 默认1. 同时同步的服务数。 concurrent-service-syncs: 1 # 默认5. 同时同步的服务帐户令牌数。 concurrent-serviceaccount-token-syncs: 5 # 默认5. 同时同步的复制控制器的数量 #concurrent-rc-syncs: 5 # 默认30s. 同步deployment的周期。 deployment-controller-sync-period: 30s # 默认15s。同步PV和PVC的周期。 pvclaimbinder-sync-period: 15s kubelet: # 集群搜索域 cluster_domain: cluster.local # 内部DNS服务器地址 cluster_dns_server: 10.43.0.254 # 禁用swap fail_swap_on: false # 扩展变量 extra_args: # 支持静态Pod。在主机/etc/kubernetes/目录下创建manifest目录,Pod YAML文件放在/etc/kubernetes/manifest/目录下 pod-manifest-path: "/etc/kubernetes/manifest/" # 指定pause镜像 pod-infra-container-image: 'rancher/pause:3.1' # 传递给网络插件的MTU值,以覆盖默认值,设置为0(零)则使用默认的1460 network-plugin-mtu: '1500' # 修改节点最大Pod数量 max-pods: "250" # 密文和配置映射同步时间,默认1分钟 sync-frequency: '3s' # Kubelet进程可以打开的文件数(默认1000000),根据节点配置情况调整 max-open-files: '2000000' # 与apiserver会话时的并发数,默认是10 kube-api-burst: '30' # 与apiserver会话时的 QPS,默认是5,QPS = 并发量/平均响应时间 kube-api-qps: '15' # kubelet默认一次拉取一个镜像,设置为false可以同时拉取多个镜像, # 前提是存储驱动要为overlay2,对应的Dokcer也需要增加下载并发数,参考[docker配置](/rancher2x/install-prepare/best-practices/docker/) serialize-image-pulls: 'false' # 拉取镜像的最大并发数,registry-burst不能超过registry-qps , # 仅当registry-qps大于0(零)时生效,(默认10)。如果registry-qps为0则不限制(默认5)。 registry-burst: '10' registry-qps: '0' cgroups-per-qos: 'true' cgroup-driver: 'cgroupfs' # 节点资源预留 enforce-node-allocatable: 'pods' system-reserved: 'cpu=0.25,memory=200Mi' kube-reserved: 'cpu=0.25,memory=1500Mi' # POD驱逐,这个参数只支持内存和磁盘。 ## 硬驱逐阈值 ### 当节点上的可用资源降至保留值以下时,就会触发强制驱逐。强制驱逐会强制kill掉POD,不会等POD自动退出。 eviction-hard: 'memory.available<300Mi,nodefs.available<10%,imagefs.available<15%,nodefs.inodesFree<5%' ## 软驱逐阈值 ### 以下四个参数配套使用,当节点上的可用资源少于这个值时但大于硬驱逐阈值时候,会等待eviction-soft-grace-period设置的时长; ### 等待中每10s检查一次,当最后一次检查还触发了软驱逐阈值就会开始驱逐,驱逐不会直接Kill POD,先发送停止信号给POD,然后等待eviction-max-pod-grace-period设置的时长; ### 在eviction-max-pod-grace-period时长之后,如果POD还未退出则发送强制kill POD" # 指定kubelet多长时间向master发布一次节点状态。注意: 它必须与kube-controller中的nodeMonitorGracePeriod一起协调工作。(默认 10s) node-status-update-frequency: 10s # 设置cAdvisor全局的采集行为的时间间隔,主要通过内核事件来发现新容器的产生。默认1m0s global-housekeeping-interval: 1m0s # 每个已发现的容器的数据采集频率。默认10s housekeeping-interval: 10s # 所有运行时请求的超时,除了长时间运行的 pull, logs, exec and attach。超时后,kubelet将取消请求,抛出错误,然后重试。(默认2m0s) runtime-request-timeout: 2m0s # 指定kubelet计算和缓存所有pod和卷的卷磁盘使用量的间隔。默认为1m0s volume-stats-agg-period: 1m0s # 可以选择定义额外的卷绑定到服务 #extra_binds: # - "/usr/libexec/kubernetes/kubelet-plugins:/usr/libexec/kubernetes/kubelet-plugins" # - "/etc/iscsi:/etc/iscsi" # - "/sbin/iscsiadm:/sbin/iscsiadm" kubeproxy: extra_args: # 默认使用iptables进行数据转发,如果要启用ipvs,则此处设置为`ipvs` proxy-mode: "ipvs" # 与kubernetes apiserver通信并发数,默认10 kube-api-burst: 20 # 与kubernetes apiserver通信时使用QPS,默认值5,QPS=并发量/平均响应时间 kube-api-qps: 10 extra_binds: scheduler: extra_args: {} extra_binds: [] extra_env: [] # 目前,只支持x509验证 ## 您可以选择创建额外的SAN(主机名或IP)以添加到API服务器PKI证书。 ## 如果要为control plane servers使用负载均衡器,这很有用。 authentication: strategy: "x509|webhook" webhook: # config_file: "...." cache_timeout: 5s sans: # 此处配置备用域名或IP,当主域名或者IP无法访问时,可通过备用域名或IP访问 - "192.168.66.101" - "kube-vip.treesir.pub" # Kubernetes认证模式 ## Use `mode: rbac` 启用 RBAC ## Use `mode: none` 禁用 认证 authorization: mode: rbac # 如果要设置Kubernetes云提供商,需要指定名称和配置,非云主机则留空; cloud_provider: # Add-ons是通过kubernetes jobs来部署。 在超时后,RKE将放弃重试获取job状态。以秒为单位。 addon_job_timeout: 30 # 有几个网络插件可以选择:`flannel、canal、calico`,Rancher2默认canal network: # rke v1.0.4+ 可用,如果选择canal网络驱动,需要设置mtu为1450 mtu: 1450 plugin: calico # 目前只支持nginx ingress controller ## 可以设置`provider: none`来禁用ingress controller ingress: provider: nginx node_selector: ingress: yes options: map-hash-bucket-size: "1024" ssl-protocols: SSLv2 # 配置dns上游dns服务器 ## 可用rke版本 v0.2.0 dns: provider: coredns upstreamnameservers: - 192.168.66.2 - 223.5.5.5 node_selector: dns: yesrke 启动集群
rke up --config ./cluster.yml部署集群,使用
kubectl进行管理mkdir ~/.kube/ ln -s `echo $PWD`/kube_config_cluster.yaml ~/.kube/config kubectl version # 看到有下面输出,表示集群搭建成功 Client Version: version.Info{Major:"1", Minor:"22", GitVersion:"v1.22.2", GitCommit:"8b5a19147530eaac9476b0ab82980b4088bbc1b2", GitTreeState:"clean", BuildDate:"2021-09-15T21:38:50Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"linux/amd64"} Server Version: version.Info{Major:"1", Minor:"21", GitVersion:"v1.21.5", GitCommit:"aea7bbadd2fc0cd689de94a54e5b7b758869d691", GitTreeState:"clean", BuildDate:"2021-09-15T21:04:16Z", GoVersion:"go1.16.8", Compiler:"gc", Platform:"linux/amd64"}配置 给 node 添加 lable,让
coredns&nginx ingress在节点中启动
kubectl label node node01 dns=yes \
&& kubectl label node master03 dns=yes
kubectl label node node01 ingress=yes \
&& kubectl label node master03 ingress=yes
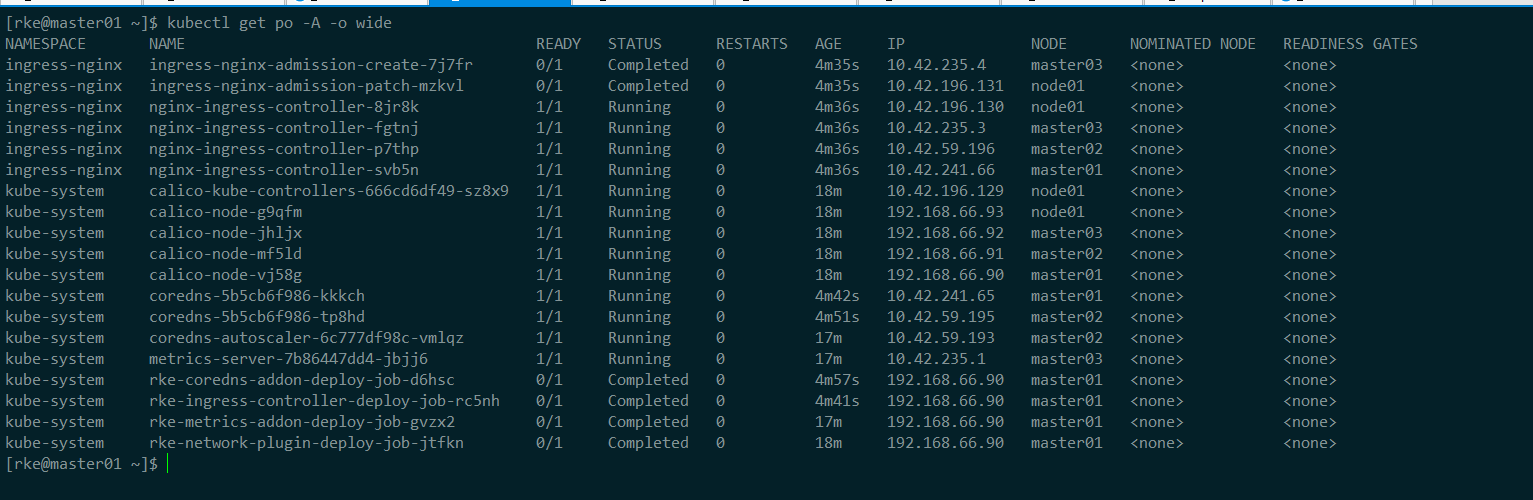
集群添加 Kube-Vip 组件#
将 rke 生成的
kube_config_cluster.yaml配置文件,Copy 至其他 master 节点中 (master01 节点执行)这一步的目的是: kube-vip pod 中需要访问自身节点中 apiserver ,来检测当前节点是否正常。
RKE_WORKSPACE=/home/rke for i in `seq 1 3`;do scp -o StrictHostKeyChecking=no "${RKE_WORKSPACE}"/kube_config_cluster.yaml master0"$i":/etc/kubernetes/admin.conf;done # Copy rke 集群配置文件至 rke 家目录中更改各节点的
/etc/kubernetes/admin.conf配置文件 (各 master 节点执行)更改当前 node 所连接的 apiserver 为 当前节点自身;示例替换
192.168.66.90根据实际情况进行更改此地址sed -i "s#192.168.66.90#$HOSTNAME#g" /etc/kubernetes/admin.conf生成
kube-vippod yaml 至 静态 pod 文件夹下 (各 master 节点执行)绑定网卡为
eth0, VIP 地址设置192.168.66.101。更具实际情况更改使用。INTERFACE=eth0 # 绑定的网卡 VIP=192.168.66.101 # apiserver VIP 地址 VIP_HOSTNAME='kube-vip.treesir.pub' # VIP 域名 IMAGE='ghcr.io/kube-vip/kube-vip:v0.3.8' # kubevip 使用镜像 cat > /etc/kubernetes/manifest/kube-vip.yaml << EOF apiVersion: v1 kind: Pod metadata: creationTimestamp: null name: kube-vip namespace: kube-system spec: containers: - args: - manager env: - name: vip_arp value: "true" - name: vip_interface value: ${INTERFACE} - name: port value: "6443" - name: vip_cidr value: "32" - name: cp_enable value: "true" - name: cp_namespace value: kube-system - name: vip_ddns value: "false" - name: svc_enable value: "true" - name: vip_leaderelection value: "true" - name: vip_leaseduration value: "5" - name: vip_renewdeadline value: "3" - name: vip_retryperiod value: "1" - name: vip_address value: ${VIP} image: "${IMAGE}" imagePullPolicy: Always name: kube-vip resources: {} securityContext: capabilities: add: - NET_ADMIN - NET_RAW - SYS_TIME volumeMounts: - mountPath: /etc/kubernetes/admin.conf name: kubeconfig - mountPath: /etc/hosts name: hosts readOnly: true hostNetwork: true volumes: - hostPath: path: /etc/kubernetes/admin.conf name: kubeconfig - name: hosts hostPath: path: /etc/hosts type: File status: {} EOF也可以使用下面这种方法进行渲染生成, yaml 文件,再对生成的 pod 文件进行修饰处理。
INTERFACE=eth0 # 绑定的网卡 VIP=192.168.66.101 # apiserver VIP 地址 docker run -it --net=host --rm --name vip plndr/kube-vip:v0.3.8 \ "manifest" "pod" "--interface" \ "$INTERFACE" "--vip" "$VIP" \ "--controlplane" "--services" \ "--arp" "--leaderElection" | tee /etc/kubernetes/manifest/kube-vip.yaml检查容器日志启动情况
docker ps|grep kube-vip|grep -v 'pause'|awk '{print $1}'|xargs -I {} docker logs -f -n 100 {}master01
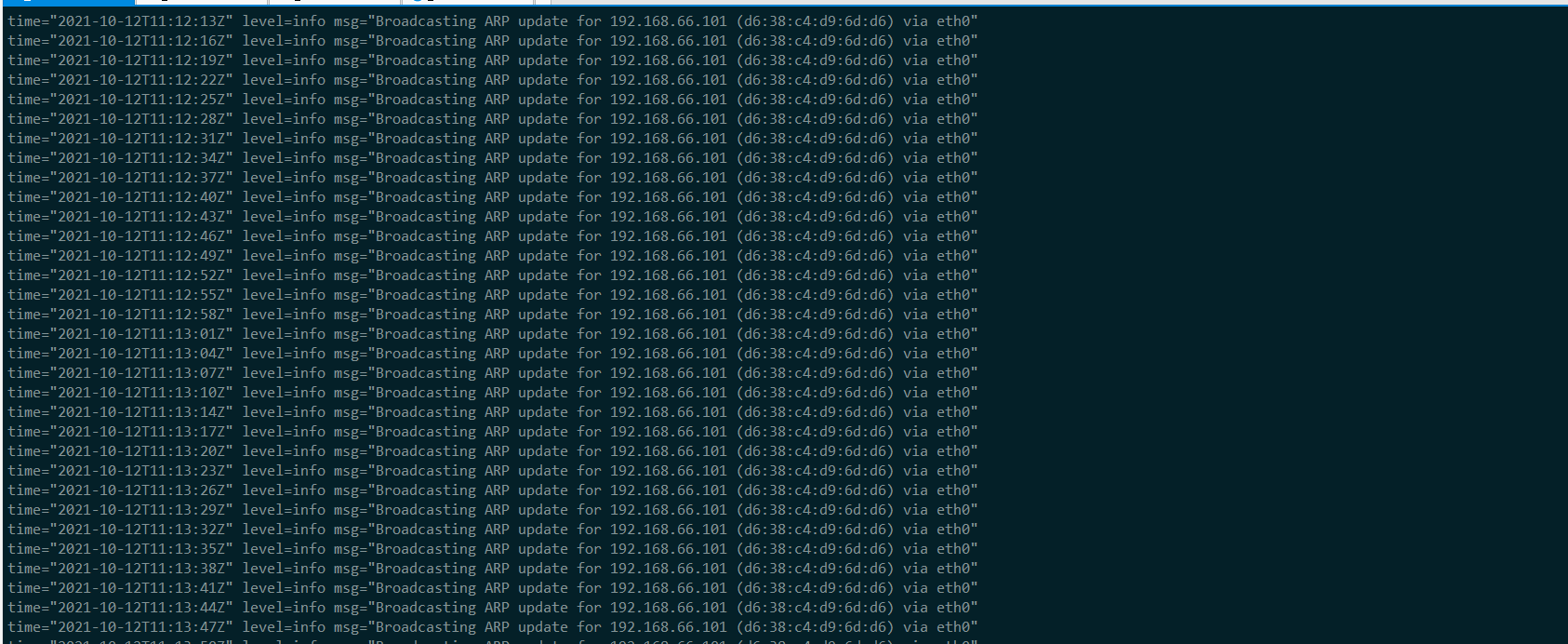
master02

master03

从上述 kube-vip pod 的日志中,可以看到 集群已正常启动,且 leader 为
master01
Kube-Vip 与客户端 kubectl 集成#
kube-vip 部署好之后,客户端 kubectl 使用的配置文件中 apiserver 地址,默认还是 rke 主控节点的地址,如主控节点此时 down 机,客户端 kubectl 将不能继续访问 apiserver,更改为 vip 的域名即可解决此问题。对于 rke
集群内部使用的 apiserver 地址,使用的是kubernetes.default.svc.cluster.local其在内部就实现了 高可用性。
添加 vip 域名
kube-vip.treesir.pub至 hosts 文件中如有
DNS基础设施服务器,添加一条A记录也可以,不想用域名的话,可以直接写192.168.66.101。如出现x509证书错误,确认是否在 rke 的authentication配置项中,将 vip 地址信息,加入至 证书链中。echo '192.168.66.101 kube-vip.treesir.pub' >> /etc/hosts更改 kubectl
~/.kube/config配置文件sed -i "s#$HOSTNAME#kube-vip.treesir.pub#g" ~/.kube/config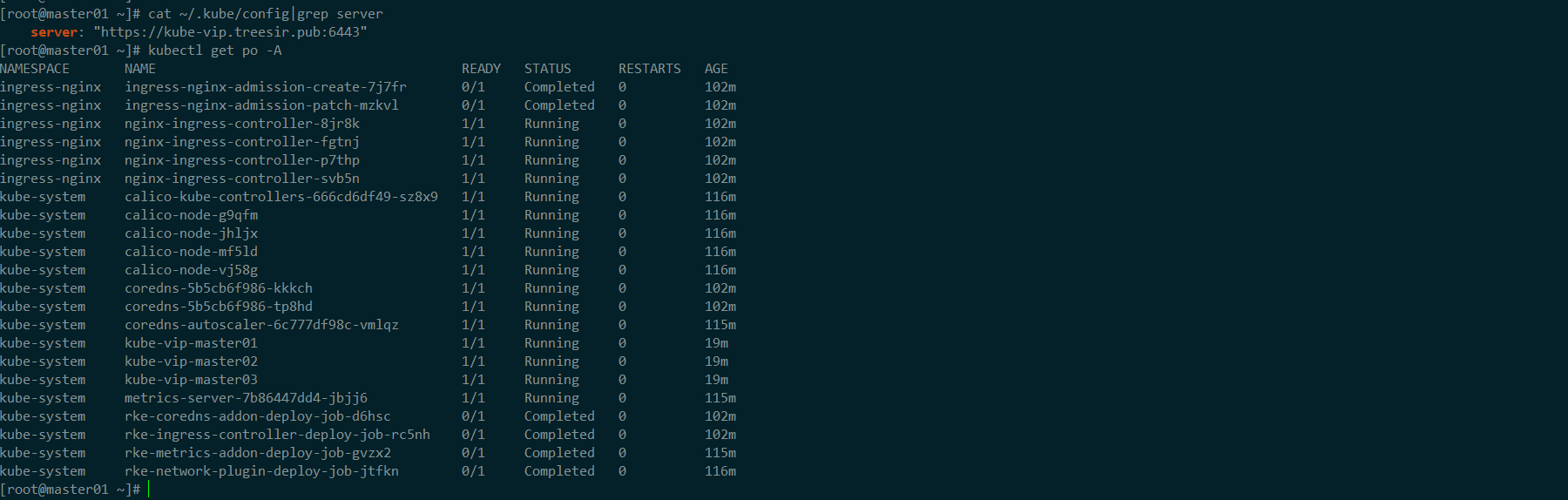
使用 vip 地址正常访问到集群信息
测试 Kube-Vip 的高可用性#
测试高可用,由于使用
rke部署集群,所有的组件多是在 docker 中,那么我们只需要将docker 服务进行关停,就可以模拟 节点 down 机。
模拟
master01节点 down 机systemctl disable docker \ && service docker stop \ && reboot # 未了防止 docker 容器未正常停止,我们多系统进行一次重启,docker 不随系统进行启动,达到目的。观察其他节点
kube-vip日志情况docker ps|grep kube-vip|grep -v 'pause'|awk '{print $1}'|xargs -I {} docker logs -f -n 100 {}
可以看到 leader 从
master01变更为了master03,切换动作在秒级内完成,用户基本无感知。测试访问集群
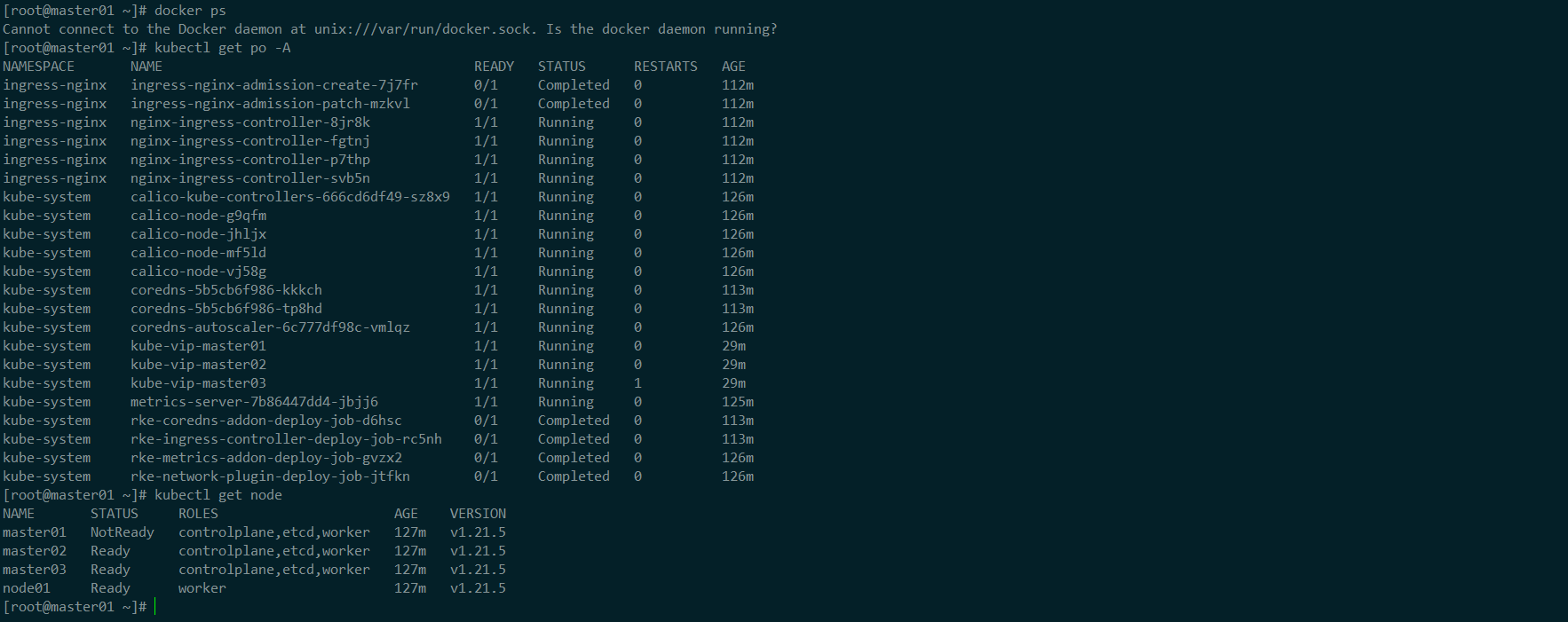
测试集群访问,没有收到丝毫的影响
Kube-Vip 作为 Loadbalance#
在将
Kube-Vip作为 Loadbalance 资源对象进行使用时,需要部署一个kube-vip-cloud-provider,官方 项目地址
部署
kube-vip-cloud-providerkubectl apply -f https://raw.githubusercontent.com/kube-vip/kube-vip-cloud-provider/main/manifest/kube-vip-cloud-controller.yaml
创建 IP 地址池,
kubevip-cm.yaml配置文件kube-vip Loadbalance 的地址池,可以针对 当个命名空间 (
cidr-<namespace>/range-<namespace>) 和全局 (cidr-global/range-global) 进行设置,支持方式可以通过子网掩码&地址范围,具体可以参考 此文档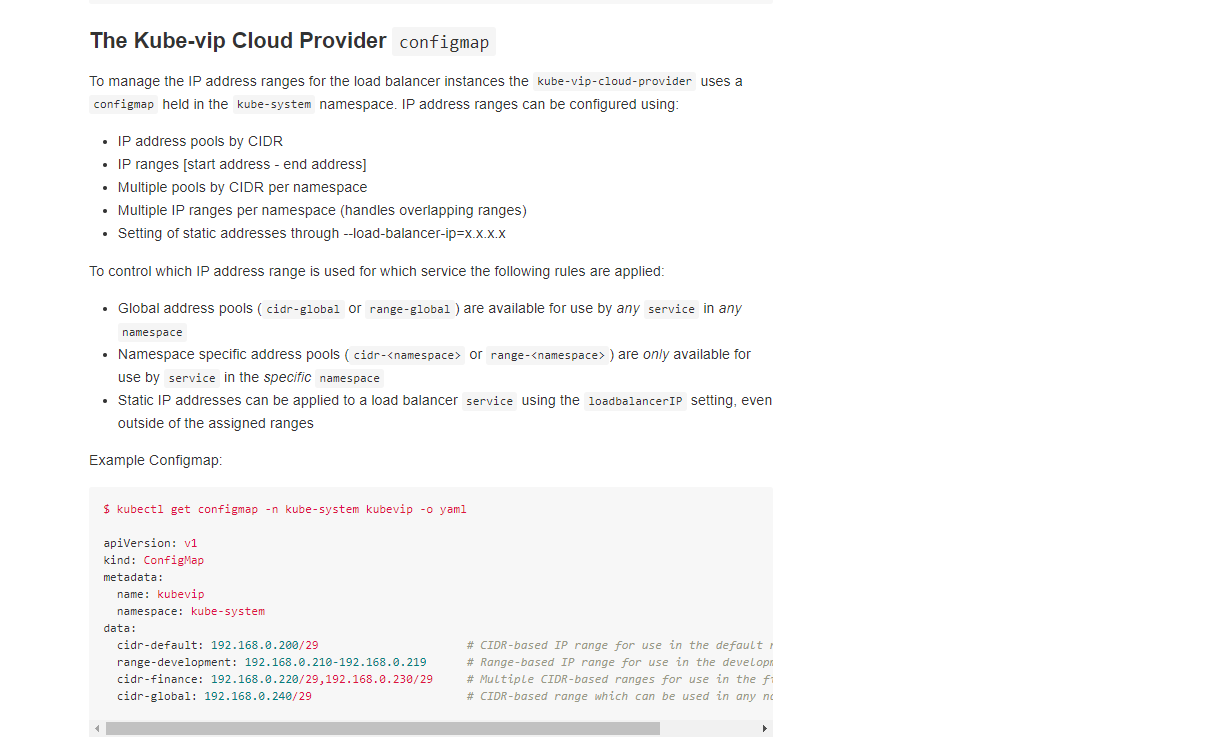
cat << EOF |tr -s "n" | tee kubevip-cm.yaml | kubectl apply -f - apiVersion: v1 kind: ConfigMap metadata: name: kubevip namespace: kube-system data: range-global: 192.168.66.210-192.168.66.219 EOF上述资源清单中我 允许 Loadbalance 在未指定
loadBalancerIP时,使用 192.168.66.210 ~ 192.168.66.21910 个 IP 地址。创建
nginx-deployment.yaml资源清单cat << EOF |tr -s "n" | tee nginx-deployment.yaml | kubectl apply -f - apiVersion: apps/v1 kind: Deployment metadata: name: nginx spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx image: nginx resources: limits: memory: "128Mi" cpu: "500m" ports: - containerPort: 80 EOF kubectl get po --watch # 等待 pod 启动完成测试将 nginx pod 已
LoadBalancerservice 类型进行暴露下面资源清单文件中不指定
loadBalancerIP的话,默认使用configmap中range-global地址池cat << EOF |tr -s "n" | tee nginx-ingress-lb | kubectl apply -f - apiVersion: v1 kind: Service metadata: name: nginx-lb spec: selector: app: nginx ports: - port: 80 targetPort: 80 type: LoadBalancer EOF kubectl get svc -o wide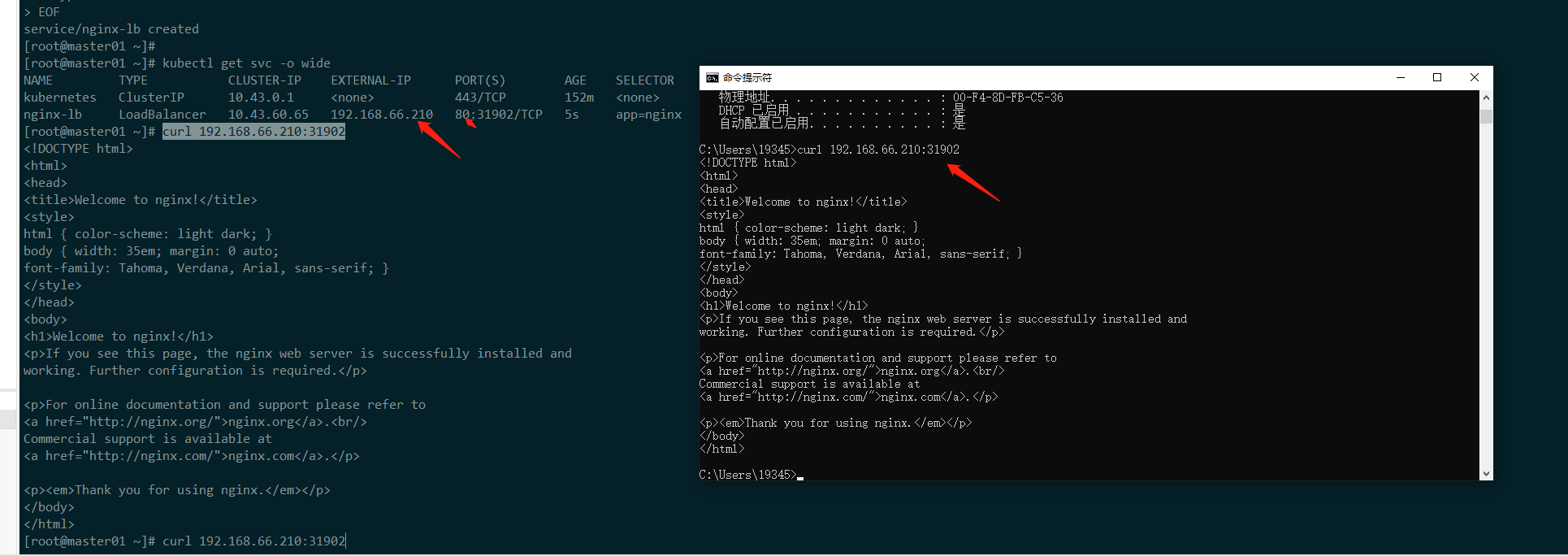
从上图中,测试使用 LoadBalancer 自动获取到的 vip 地址,来访问 pod,可以看到链路是正常可以走通的。
查看 kube-vip leader 日志
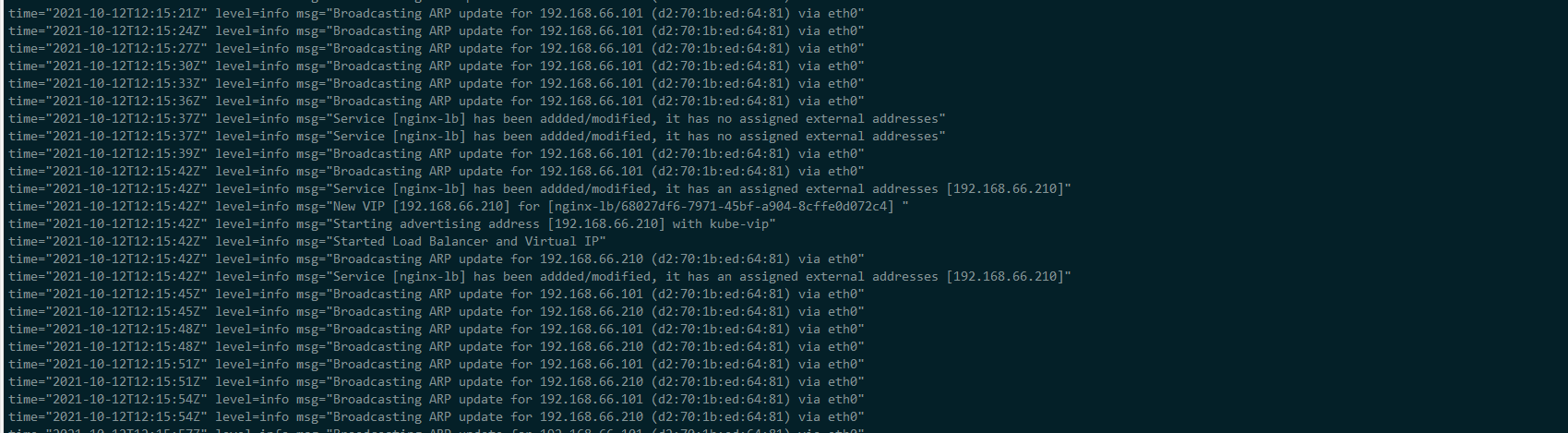
从上图中,可以看到 kube-vip leader 新增了刚才,
nginx-lbLoadBalancer 资源对象自动获取到的 vip 地址,并将其绑定在了自己的 eth0 接口中。除了可以使用 地址池之外,还可以将 loadBalancerIP 写成静态的,方法如下apiVersion: v1 kind: Service metadata: name: nginx-lb spec: selector: app: nginx ports: - port: 80 targetPort: 80 type: LoadBalancer loadBalancerIP: "192.168.66.101"
验证 kube-vip LoadBalancer 流量特征#
kube-vip 流量会将未匹配的流量,全路由给
leader,匹配到的流量将转发给对应的service。这样说可能有点抽象,这里进行实际验证一下。这里就已刚才上面nginx-lb,自动获取的192.168.66.210vip 地址做示例。
验证无法匹配的流量
这里我们使用 ssh 进行远程验证,ssh 默认工作在
22端口,集群中目前 我们是没有匹配的service规则。ssh root@192.168.66.210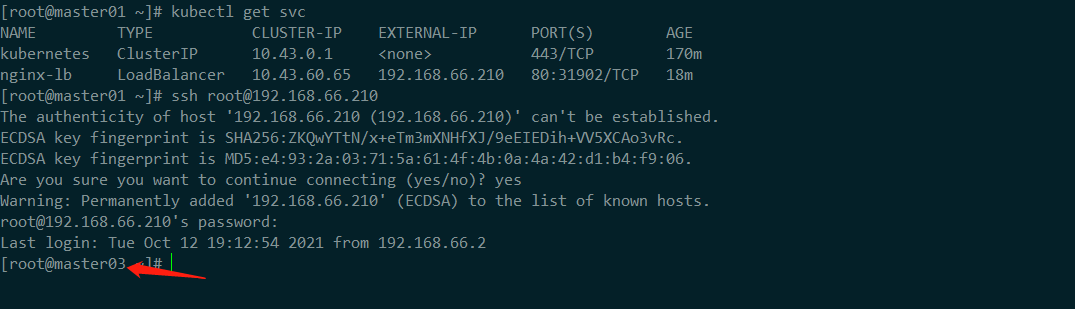
从图中,我们可以验证流量是给了 kube-vip 的 leader 上的
sshd,但是还不能确定。我们让 kube-vip leader 主动发生切换动作,再远程来看看。关闭 master03 中的 kube-vip
把对应节点中的
/etc/kubernetes/manifest/下资源清单给移走,kubelet 会自动删除对应 pod。mv /etc/kubernetes/manifest/kube-vip.yaml /tmp/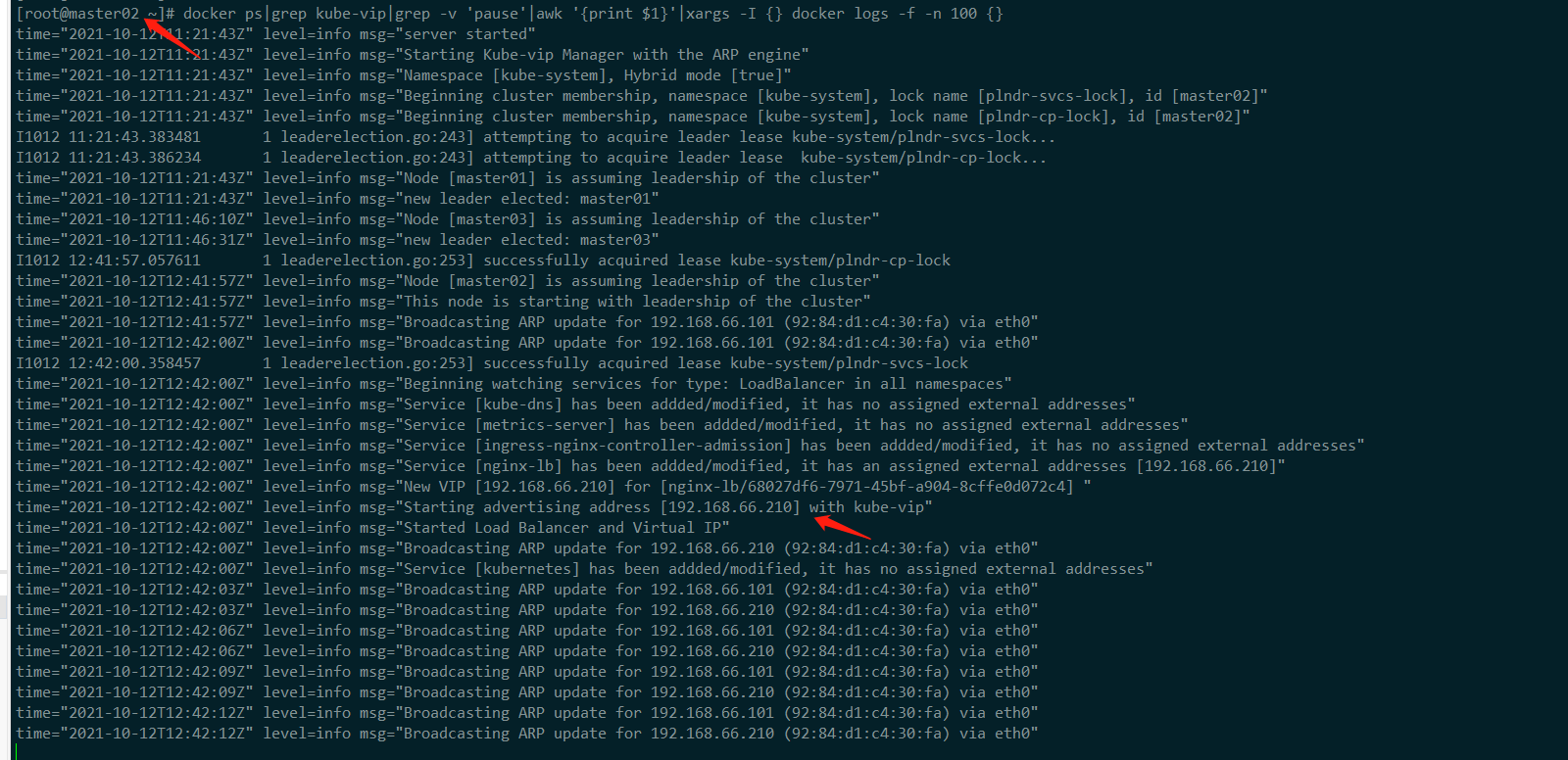
现在变成 leader 变成
master02了 再远程一下看看。
验证匹配的流量
这里将 LoadBalancer service 中的 端口改为 22,同样已 ssh 的端口进行测试
cat << EOF |tr -s "n" | tee nginx-ingress-lb | kubectl apply -f - apiVersion: v1 kind: Service metadata: name: nginx-lb spec: selector: app: nginx ports: - port: 22 # 改成 ssh port targetPort: 80 type: LoadBalancer EOF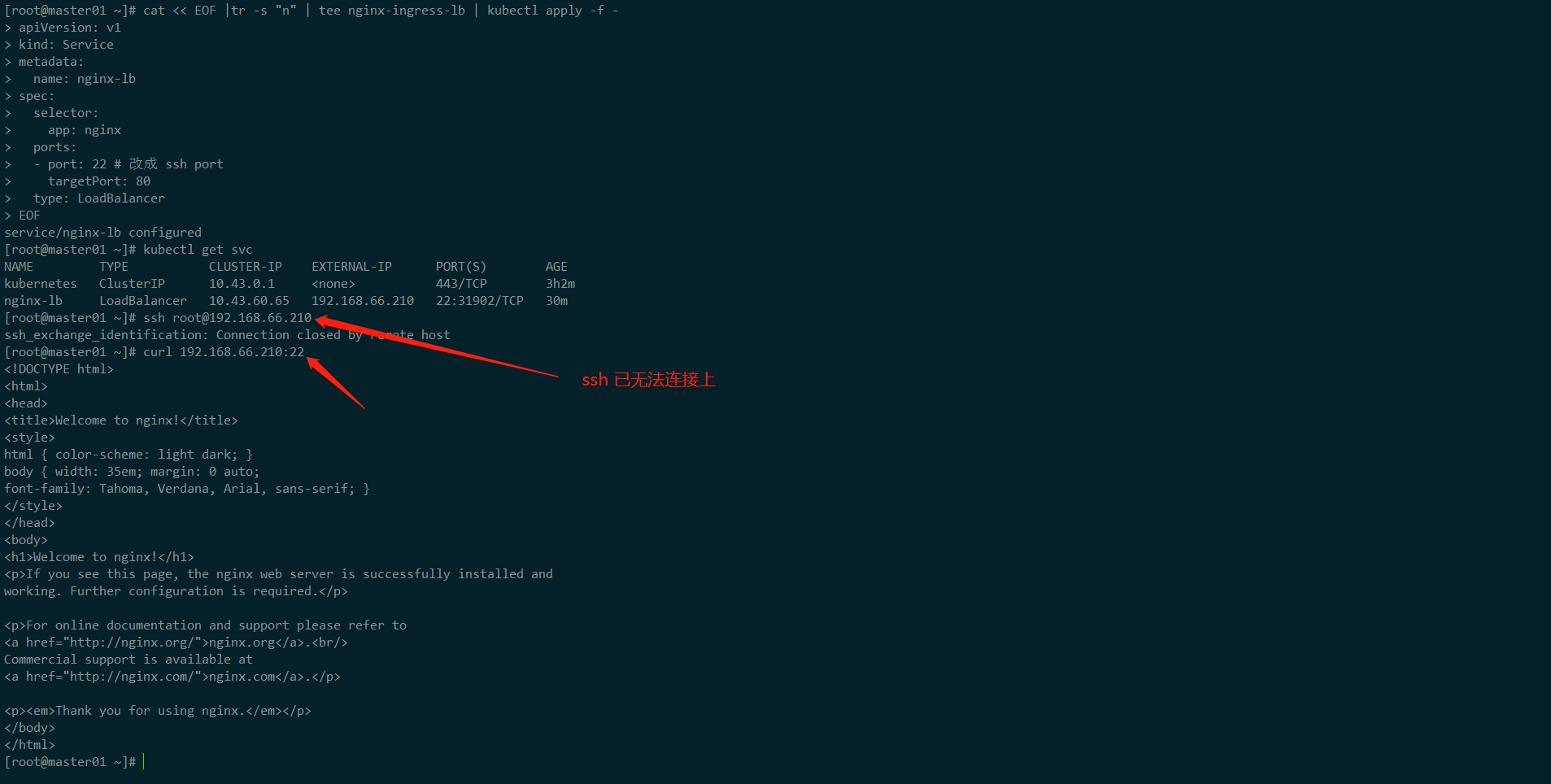
参考文档#
https://www.treesir.pub/post/kube-vip-deploy-ha-k8s-cluster/
https://kube-vip.io/usage/on-prem/
总结#
在以前的情况下,实现 HA 需要部署外部的服务来支持,比如:nginx、haproxy、keepalived、lvs ; 通过 kube-vip 在没有其他额外的节点的情况下可以使用简单的配置实现集群外部访问 apiserver 的高可用, 并且能够很方便的对接 Kubernetes 的 LoadBalancer Service,如果我们将 ingress service 绑定在 LoadBalancer vip 中,就实现了外部流量访问的高可用性。在上生产前还是需要针对应用场景进行一下性能测试,在某些应用场景下没有专门的负载均衡器功能那么强大,且目前自身暂还不支持流量的负载功能。